
图遍历是几乎所有图论算法的基础机制。它是系统地访问、检查、分析以及经常更新图中每个顶点(节点)的过程。无论你是在谷歌地图中寻找最短路径、在社交网络上推荐好友、为搜索引擎抓取互联网内容,还是通过算法解决复杂的谜题,你都在使用图遍历。
这一领域的核心是两个传奇算法:广度优先搜索 (Breadth-First Search, BFS) 和 深度优先搜索 (Depth-First Search, DFS)。虽然它们都保证将完全访问连通分量中每个可达的节点一次,但它们访问节点的顺序和策略导致了截然不同的应用、时间/空间复杂度以及行为模式。
在这篇综合指南中,我们将剖析这两种算法,检查它们的数据结构,审查实现代码,比较它们的复杂度,最后查看真实场景,帮助你有信心地回答那个终极问题:"我什么时候应该使用 BFS,什么时候应该使用 DFS?"
1. 深入广度优先搜索 (BFS)
广度优先搜索以同心圆的"波纹"方式探索图。它从选定的根节点(或任何起始节点)开始,首先访问其所有直接相邻的邻居。只有在完全穷尽距离正好为 1 条边的所有节点之后,它才会移动到距离为 2 的节点,依此类推。
水滴类比: 将 BFS 想象成水滴在平静的池塘中产生涟漪。涟漪在所有方向上均匀向外扩展。它不会沿直线射出;它按半径均匀地覆盖区域。
BFS 的机制
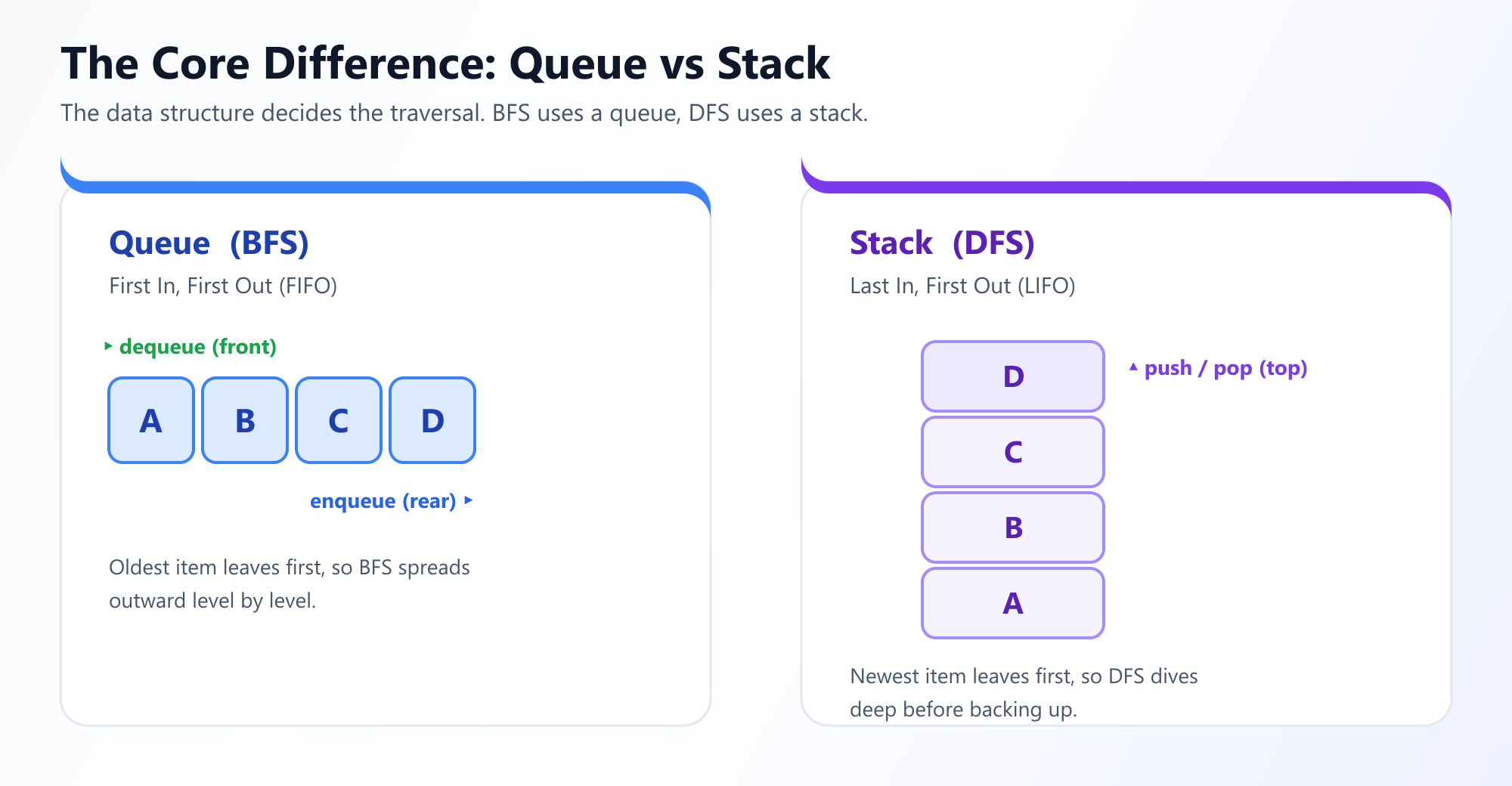
为了确保严格按层访问节点,BFS 依赖于一种 队列 (Queue)(先进先出,即 FIFO)数据结构来记录接下来应该访问哪些节点。
标准 BFS 算法遵循以下步骤:
- 初始化一个队列和一个布尔数组(或 Hash Set)以跟踪
已访问的节点。 - 将起始节点排入队列并立即将其标记为
已访问。 - 开始一个循环,只要队列不为空就继续。
- 从队列前端取出节点。这是你当前的节点。按你希望的方式处理它。
- 遍历此当前节点的每个相邻邻居。
- 如果邻居尚未被访问,则将其标记为
已访问并将其排入队列。 - 重复直到队列为空。
BFS 实现示例
下面是一个使用邻接表表示法和高效的 collections.deque 在 Python 中清晰实现 BFS 的示例。
from collections import deque
def breadth_first_search(graph, start_node):
# 初始化一个队列和一个集合用于存放已访问节点
queue = deque([start_node])
visited = {start_node}
# 存储遍历顺序
traversal_order = []
while queue:
# 从队列前端取出节点
current_node = queue.popleft()
traversal_order.append(current_node)
# 获取出队节点的所有相邻节点
for neighbor in graph[current_node]:
if neighbor not in visited:
# 立即在入队之前标记为已访问
# 避免队列中出现重复条目
visited.add(neighbor)
queue.append(neighbor)
return traversal_order
# 示例图 (邻接表)
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
print(breadth_first_search(graph, 'A'))
# 输出: ['A', 'B', 'C', 'D', 'E', 'F']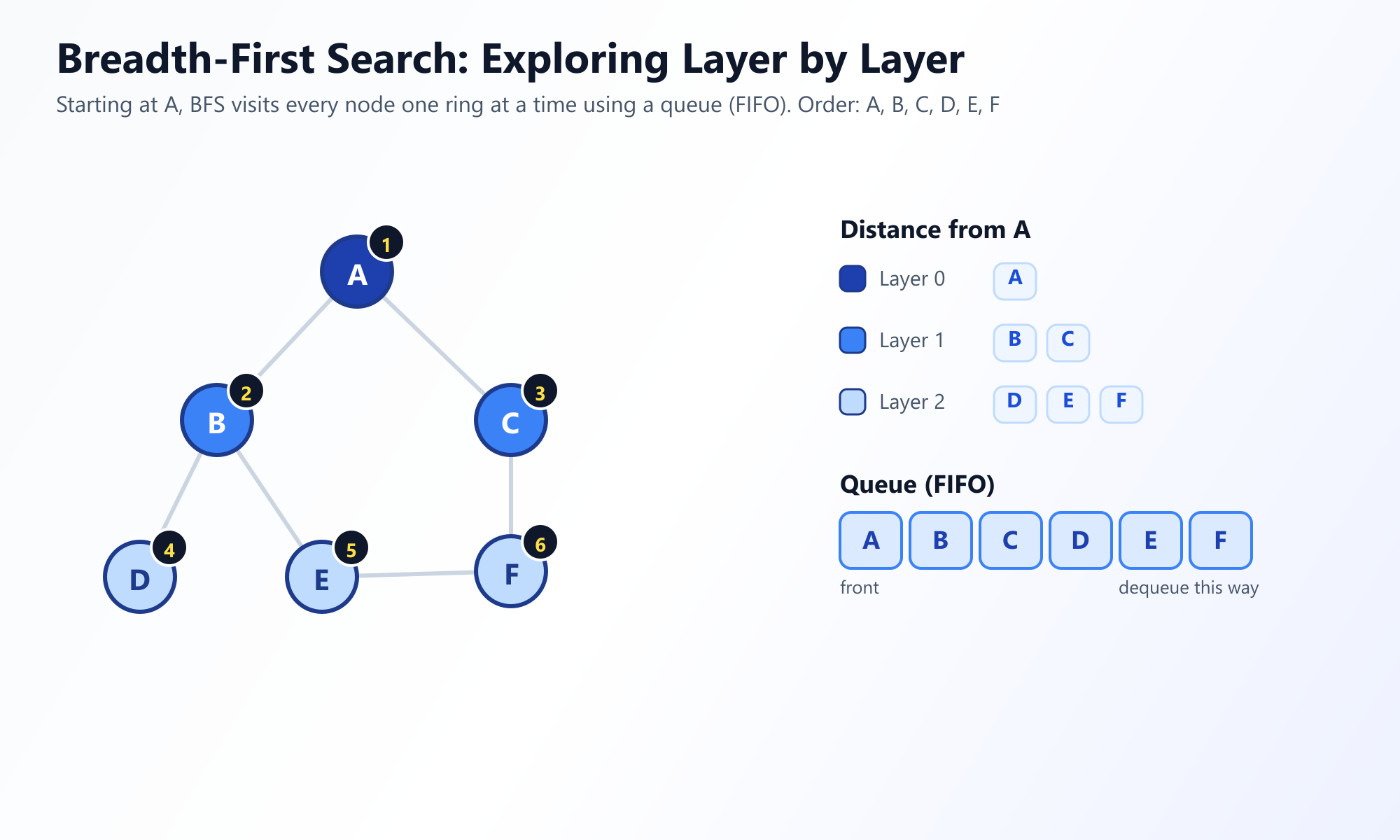
2. 深入深度优先搜索 (DFS)
深度优先搜索采取了截然不同且更具攻击性的方法。它不是广度优先地探索,而是深度优先地探索。它从根节点开始,尽可能沿着单一分支探索,直到遇到"死胡同"(一个没有未访问邻居的节点)。一旦卡住,它就会在路径上 回溯 (backtrack) 足够高,找到一个新的未探索分支,顺着探索下去。
迷宫类比: 将 DFS 想象成在物理迷宫中导航。你把右手放在右墙上,一直向前走。你拐过一个又一个弯,直到遇到死胡同。此时,你转身,走回上一个十字路口,选择那条未探索的道路。
DFS 的机制
因为 DFS 需要记住它来自哪里以便能够回溯,所以它使用一种 栈 (Stack)(后进先出,即 LIFO)数据结构。通常,开发人员会递归地实现 DFS,优雅地使用原生 CPU 调用栈,而不是手动创建 Stack 对象。
标准递归 DFS 算法遵循以下步骤:
- 从当前节点开始并立即将其标记为
已访问。 - 处理节点(例如打印其值)。
- 遍历它的所有相邻邻居。
- 如果某个邻居未被访问,就在该邻居上递归调用 DFS 函数。
- 当循环结束(没有未访问的邻居留下),函数返回,自动回溯到调用栈中前一个调用者。
DFS 实现示例
下面是一个使用 Python 的优雅的递归 DFS 实现。
def depth_first_search_recursive(graph, current_node, visited=None, traversal_order=None):
# 初始化集合和列表
if visited is None:
visited = set()
if traversal_order is None:
traversal_order = []
# 将当前节点标记为已访问并记录
visited.add(current_node)
traversal_order.append(current_node)
# 递归访问所有未访问的邻居
for neighbor in graph[current_node]:
if neighbor not in visited:
depth_first_search_recursive(graph, neighbor, visited, traversal_order)
return traversal_order
# 示例图 (邻接表)
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
print(depth_first_search_recursive(graph, 'A'))
# 输出: ['A', 'B', 'D', 'E', 'F', 'C']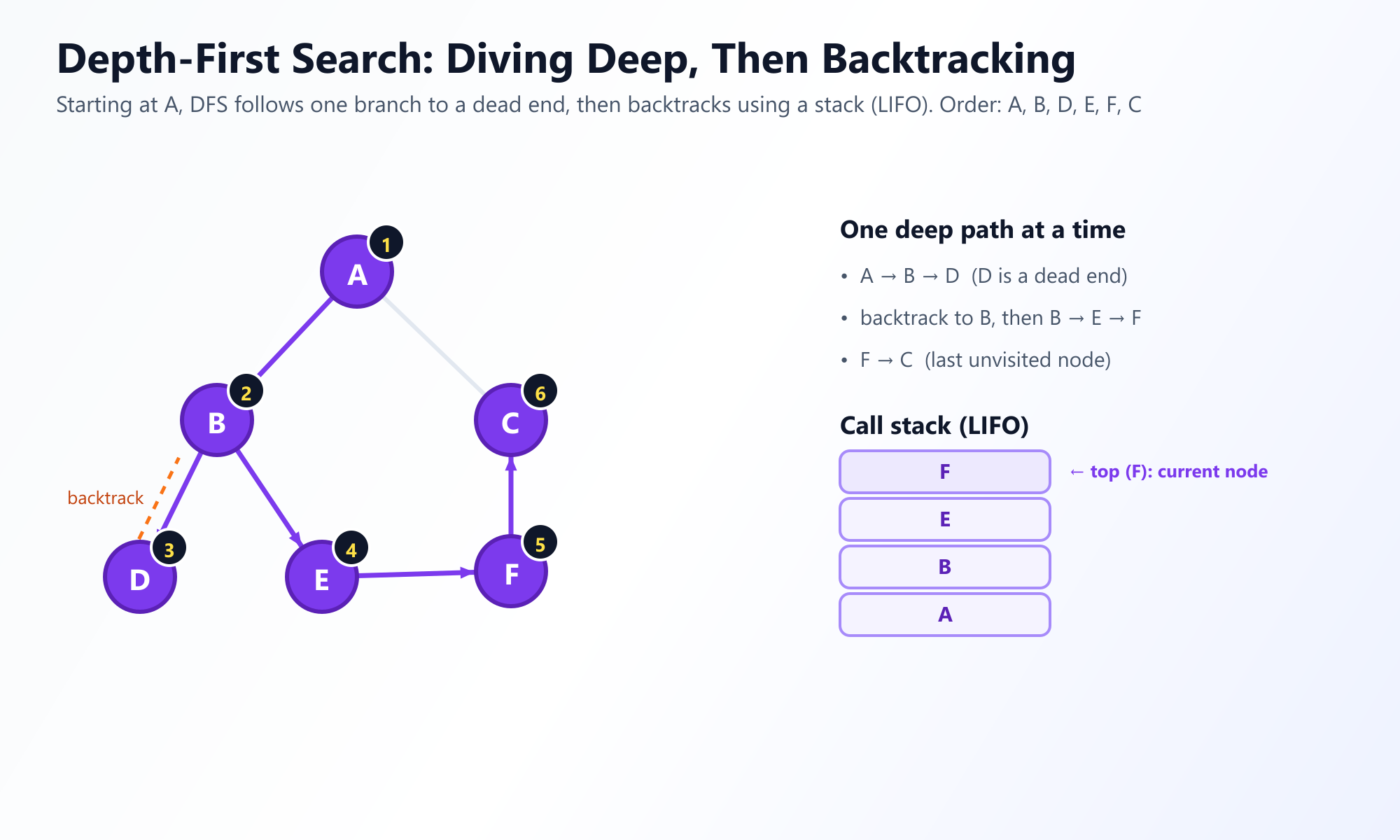
注意输出结果与 BFS 的不同。DFS 积极追随从 A 到 B 到 D 的路径,然后才开始回溯。
3. BFS vs. DFS:终极比较
在技术面试和实际系统设计中,选择错误的遍历算法可能会导致灾难性的内存耗尽或极其低效的执行时间。让我们分解技术差异。
| 指标 | 广度优先搜索 (BFS) | 深度优先搜索 (DFS) |
|---|---|---|
| 数据结构 | 队列 (FIFO) - 迭代方法 | 栈 (LIFO) - 通常是递归方法 |
| 时间复杂度 | O(V + E)必须访问每个顶点并检查每条边。 |
O(V + E)同样访问每个顶点并探索每条边。 |
| 空间复杂度 | O(W) 其中 W 是图的最大宽度。在最坏情况下密集图中可能为 O(V)。 |
O(H) 其中 H 是图的最大深度/高度。如果图是一条长直线,可能为 O(V)。 |
| 最短路径保证 | 是。 对于无权图,BFS 保证能找到最短路径。 | 否。 DFS 可能会在找到直达的短路径之前找到一条巨大而曲折的路径。 |
| 内存开销 | 如果树/图非常宽(例如社交网络),则开销很高。队列必须容纳当前层的所有节点。 | 如果树/图非常深,则开销很高。调用栈必须容纳当前节点的所有祖先。 |
| 最优性 | 最适合寻找靠近源的目标。 | 最适合寻找远离源的目标或探索所有可能性。 |
理解空间复杂度的权衡
虽然这两种算法的共同时间复杂度都是 O(V + E),但它们的空间复杂度根据图的拓扑结构有很大差异。
- 宽图: 如果图有巨大的分支因子(例如 HTML DOM 树或 Twitter 关注者图),则 BFS 队列会膨胀,因为它必须一次存储整个"层"的图。在这些场景中,DFS 内存效率很高。
- 深图: 如果图极深(例如庞大的区块链或很深的决策树),则 DFS 可能超过最大递归深度或消耗过多栈内存。在这些场景中,BFS 可能更可取,尽管迭代加深 DFS 通常是生产中使用的解决方案。
4. 实际应用:何时使用哪个?
BFS 和 DFS 之间的选择通常归结为你试图从图结构中提取什么。
使用广度优先搜索 (BFS) 的情况:
- 寻找最短路径(无权图): 因为 BFS 逐层探索,所以当它第一次遇到目标节点时,它绝对采取了到达那里的最小边数。出于这个原因,GPS 路由算法通常使用 BFS 变体(如 Dijkstra)。
- 目标可能靠近源头: 如果你在家谱中寻找一个堂兄弟,BFS 会立刻找到它。DFS 可能会沿着完全不同的家族分支探索到 16 世纪,然后才去查看那个堂兄。
- 点对点网络: 像 BitTorrent 这样的协议使用 BFS 寻找相邻节点。"寻找 1 跳范围内的所有对等点,然后寻找 2 跳范围内的所有对等点。"
- 网络爬虫: 像谷歌这样的搜索引擎最初使用 BFS 爬取网络。你想在深入探索嵌套和晦涩的子页面之前索引主页上最突出的链接。
- 社交网络上的"六度分隔": 像领英的"二度联系"功能完全依赖于有边界的 BFS。
使用深度优先搜索 (DFS) 的情况:
- 检查循环存在性: DFS 特别适合寻找后向边(指向祖先的边)。如果存在后向边,则该图有循环。这对于防止路由器中出现无限循环和检测操作系统中的死锁至关重要。
- 拓扑排序: 在构建系统中(如 Make、Webpack 或 npm),任务具有依赖性。DFS 用于对这些任务进行线性排序,以便每个任务只在其依赖项满足后执行。
- 内存非常有限(且图很宽): 正如所讨论的,DFS 只需要存储从根到当前节点的路径,这使得它对于宽广宏大的图(如游戏状态树,如国际象棋引擎)具有难以置信的内存效率。
- 解决谜题和迷宫: DFS 是解决数独、N 皇后问题或解决物理迷宫的首选算法。它积极探索可能的解决方案,如果失败,则简单地回溯并尝试下一个配置。
- 寻找强连通分量: 像 Tarjan 算法或 Kosaraju 算法严重依赖 DFS 将节点聚类到强连接块中。
5. 高级变体
在现代计算中,基础的 BFS 和 DFS 通常会被增强以处理大规模数据。
- 双向 BFS: 你不用从源点向终点运行一次 BFS,而是运行两个同步的 BFS 波动,一个从源点开始,一个从终点开始。当这两波相交时,你就找到了最短路径。这极大地缩小了搜索空间。
- 迭代加深 DFS (IDDFS): 这结合了 DFS 的内存效率和 BFS 的最短路径保证。它运行 DFS,但设定了严格的深度限制。如果未找到目标,它会增加深度限制并重新开始。这在人工智能和游戏树分析中被大量使用。
结论
广度优先搜索和深度优先搜索是图论无可争议的基石。BFS 是你逐层扩散的波动,非常适合最短路径和广阔的网络分析。DFS 是你高效利用内存、极具攻击性的迷宫跑者,非常适合检测循环、拓扑排序和深度解谜。
掌握这两种算法对于通过顶级科技公司的技术面试并设计强大、可扩展的软件架构是不可协商的。
常见问题
我应该在什么时候选择广度优先搜索 (BFS) 而不是深度优先 (DFS)?
在无权图中寻找最短路径,或者寻找距离起点较近的目标节点时,首选广度优先搜索 (BFS)。
DFS 相比 BFS 在哪些场景下更有优势?
深度优先搜索 (DFS) 更适合探索所有可能路径(如迷宫求解)、拓扑排序、环检测,或者当内存受限时,因为 DFS 在深层图中的内存开销通常较小。
BFS 和 DFS 使用的数据结构有什么不同?
BFS 使用队列(Queue,先进先出)来进行按层遍历;DFS 使用栈(Stack,后进先出),在代码实现中通常以递归的方式隐式表达。