
Inhaltsverzeichnis
Die Graphendurchsuchung ist der grundlegende Mechanismus fast aller Algorithmen der Graphentheorie. Es ist der systematische Prozess des Besuchens, Überprüfens, Analysierens und oft Aktualisierens jedes Knotens in einem Graphen. Egal, ob Sie die kürzeste Route auf Google Maps finden, Freunde in einem sozialen Netzwerk empfehlen, das Internet für eine Suchmaschine durchsuchen oder ein komplexes Rätsel algorithmisch lösen, Sie verwenden die Graphendurchsuchung.
Im Zentrum dieses Bereichs stehen zwei legendäre Algorithmen: Breitensuche (Breadth-First Search, BFS) und Tiefensuche (Depth-First Search, DFS). Obwohl beide garantieren, dass jeder erreichbare Knoten in einer zusammenhängenden Komponente genau einmal besucht wird, führen die Reihenfolge und die Strategie, mit der sie Knoten besuchen, zu drastisch unterschiedlichen Anwendungen, Zeit-/Platzkomplexitäten und Verhaltensmustern.
In diesem umfassenden Leitfaden werden wir beide Algorithmen analysieren, ihre Datenstrukturen untersuchen, Implementierungscode überprüfen, ihre Komplexitäten vergleichen und schließlich reale Szenarien betrachten, um Ihnen zu helfen, die ultimative Frage sicher zu beantworten: "Wann sollte ich BFS verwenden und wann DFS?"
1. Tiefer Einblick in die Breitensuche (BFS)
Die Breitensuche erkundet den Graphen in konzentrischen "Wellen". Sie beginnt an einem ausgewählten Wurzelknoten (oder einem beliebigen Startknoten) und besucht zuerst alle unmittelbaren Nachbarn. Erst nachdem alle Knoten in einer Entfernung von genau 1 Kante vollständig abgearbeitet sind, geht sie zu Knoten in der Entfernung 2 über und so weiter.
Die Wassertropfen-Analogie: Stellen Sie sich BFS wie einen Wassertropfen vor, der Wellen in einem stillen Teich erzeugt. Die Welle dehnt sich gleichmäßig in alle Richtungen aus. Sie schießt nicht in einer geraden Linie ab; sie bedeckt den Bereich gleichmäßig nach Radius.
Die Mechanik von BFS
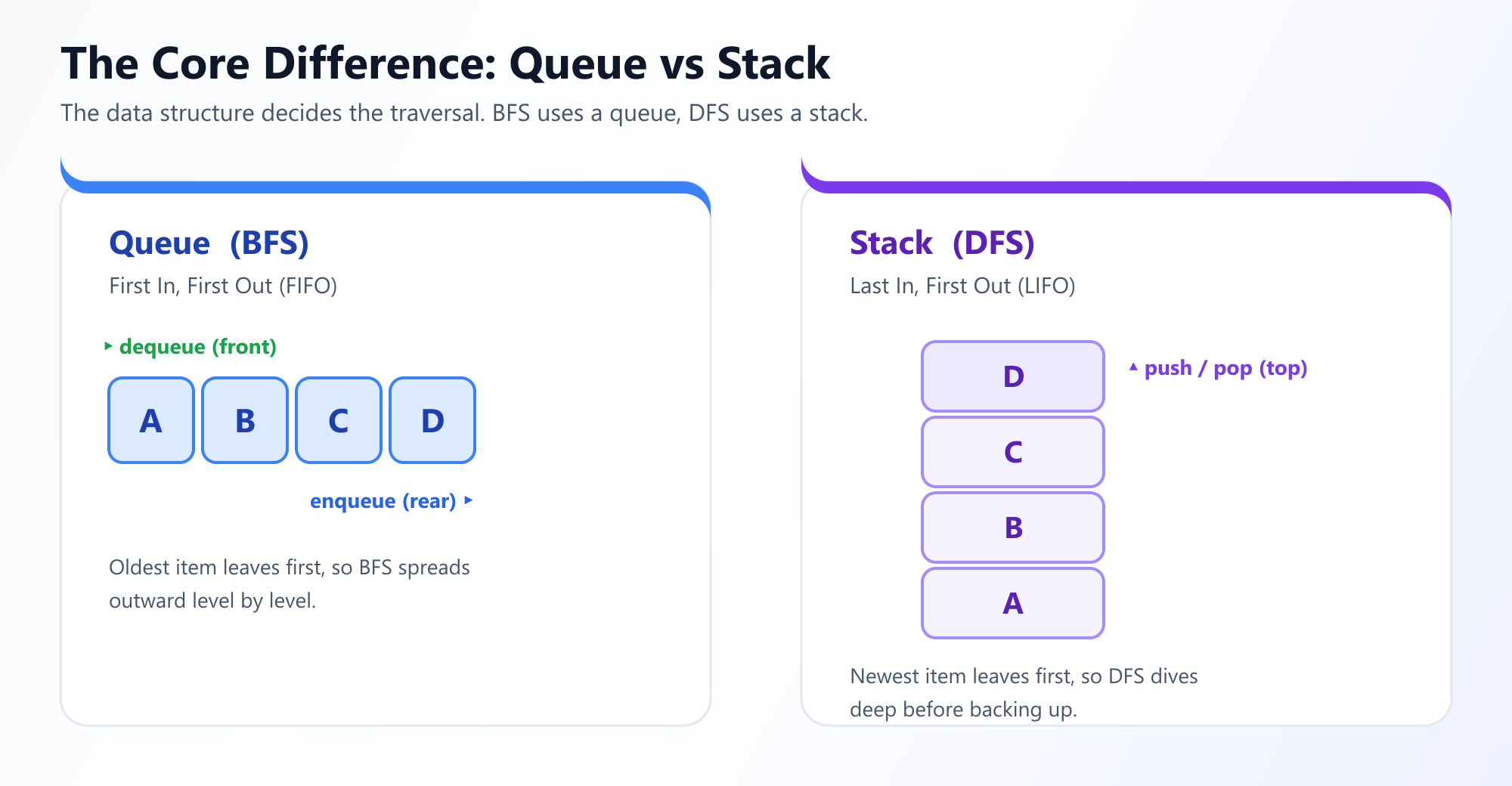
Um sicherzustellen, dass Knoten in dieser streng schichtweisen Art und Weise besucht werden, verlässt sich BFS auf eine Warteschlange (Queue) (First-In, First-Out oder FIFO) Datenstruktur, um zu verfolgen, welche Knoten als Nächstes besucht werden sollen.
Der Standard-BFS-Algorithmus folgt diesen Schritten:
- Initialisieren Sie eine Warteschlange und ein boolesches Array (oder Hash-Set), um die
besuchten (visited)Knoten zu verfolgen. - Reihen Sie den Startknoten in die Warteschlange ein und markieren Sie ihn sofort als
besucht. - Beginnen Sie eine Schleife, die so lange andauert, wie die Warteschlange nicht leer ist.
- Nehmen Sie den vordersten Knoten aus der Warteschlange. Dies ist Ihr aktueller Knoten. Verarbeiten Sie ihn wie gewünscht.
- Iterieren Sie über jeden benachbarten Nachbarn dieses aktuellen Knotens.
- Wenn ein Nachbar noch nicht besucht wurde, markieren Sie ihn als
besuchtund reihen Sie ihn in die Warteschlange ein. - Wiederholen Sie dies, bis die Warteschlange leer ist.
BFS Implementierungsbeispiel
Unten ist eine saubere Implementierung von BFS in Python mit einer Adjazenzlisten-Darstellung und der hocheffizienten collections.deque.
from collections import deque
def breadth_first_search(graph, start_node):
# Initialisiere eine Warteschlange und eine Menge für besuchte Knoten
queue = deque([start_node])
visited = {start_node}
# Speichere die Durchlaufreihenfolge
traversal_order = []
while queue:
# Knoten vorne aus der Warteschlange entfernen
current_node = queue.popleft()
traversal_order.append(current_node)
# Alle benachbarten Knoten des entfernten Knotens abrufen
for neighbor in graph[current_node]:
if neighbor not in visited:
# Sofort als besucht markieren, BEVOR man einreiht
# um doppelte Einträge in der Warteschlange zu vermeiden
visited.add(neighbor)
queue.append(neighbor)
return traversal_order
# Beispiel-Graph (Adjazenzliste)
graph = {
'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']
}
print(breadth_first_search(graph, 'A'))
# Ausgabe: ['A', 'B', 'C', 'D', 'E', 'F']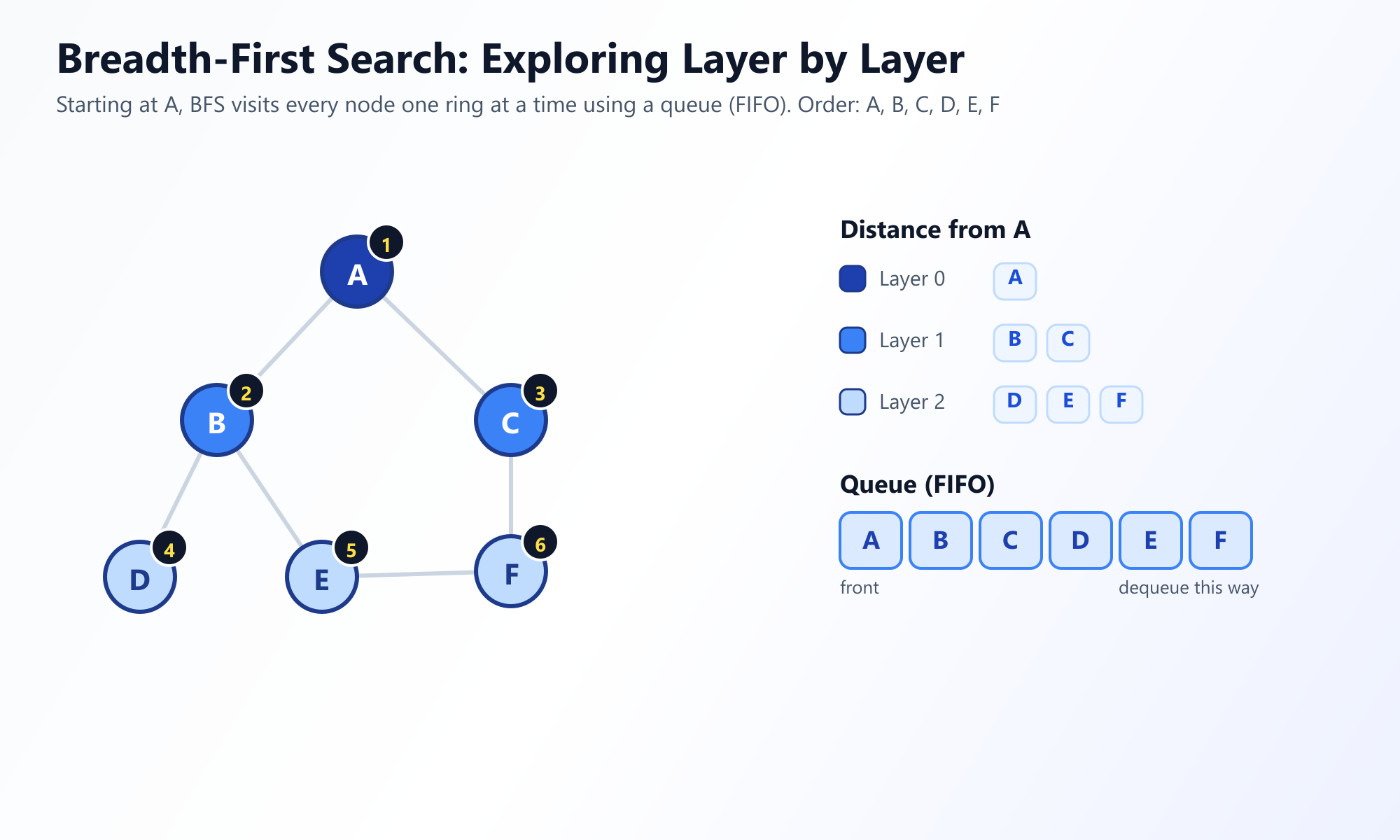
Hören Sie auf zu lesen, beginnen Sie zu visualisieren
Code zu lesen ist gut, aber dem Algorithmus in Echtzeit bei der Ausführung zuzusehen, baut wahre Intuition auf. Sehen Sie sich an, wie die Warteschlange die BFS-Welle auf unserer Plattform steuert.
Interaktiven BFS-Visualisierer starten2. Tiefer Einblick in die Tiefensuche (DFS)
Die Tiefensuche wählt einen drastisch anderen, aggressiveren Ansatz. Anstatt breit zu erkunden, erkundet sie tief. Sie beginnt an einem Wurzelknoten und erkundet so weit wie möglich entlang eines einzelnen Zweiges, bis sie auf eine "Sackgasse" trifft (ein Knoten ohne unbesuchte Nachbarn). Sobald sie feststeckt, zieht sie sich zurück oder macht einen Rückzieher (Backtracking) den Pfad hinauf, gerade genug, um einen neuen, unerforschten Zweig zu finden, in den sie abtauchen kann.
Die Labyrinth-Analogie: Stellen Sie sich DFS wie die Navigation durch ein physisches Labyrinth vor. Sie legen Ihre Hand an die rechte Wand und gehen weiter vorwärts. Sie biegen immer wieder ab, bis Sie eine Sackgasse erreichen. An diesem Punkt drehen Sie sich um, gehen zurück zur letzten Kreuzung und nehmen den unerforschten Weg.
Die Mechanik von DFS
Da DFS sich daran erinnern muss, woher sie kam, um zurückverfolgen zu können, nutzt sie eine Stapel (Stack) (Last-In, First-Out oder LIFO) Datenstruktur. Am häufigsten implementieren Entwickler DFS rekursiv und nutzen elegant den nativen Aufrufstapel der CPU, anstatt ein manuelles Stapelobjekt zu erstellen.
Der rekursive Standard-DFS-Algorithmus folgt diesen Schritten:
- Beginnen Sie am aktuellen Knoten und markieren Sie ihn sofort als
besucht. - Verarbeiten Sie den Knoten (z. B. geben Sie seinen Wert aus).
- Iterieren Sie über alle seine benachbarten Nachbarn.
- Wenn ein Nachbar noch nicht besucht wurde, rufen Sie die DFS-Funktion rekursiv für diesen Nachbarn auf.
- Wenn die Schleife beendet ist (keine unbesuchten Nachbarn übrig), kehrt die Funktion zurück und verfolgt automatisch zum vorherigen Aufrufer auf dem Stapel zurück.
DFS Implementierungsbeispiel
Unten ist eine elegante rekursive Implementierung von DFS in Python.
def depth_first_search_recursive(graph, current_node, visited=None, traversal_order=None):
# Kollektionen beim ersten Aufruf initialisieren
if visited is None:
visited = set()
if traversal_order is None:
traversal_order = []
# Markiere den aktuellen Knoten als besucht und zeichne ihn auf
visited.add(current_node)
traversal_order.append(current_node)
# Alle unbesuchten Nachbarn rekursiv besuchen
for neighbor in graph[current_node]:
if neighbor not in visited:
depth_first_search_recursive(graph, neighbor, visited, traversal_order)
return traversal_order
# Beispiel-Graph (Adjazenzliste)
graph = {
'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']
}
print(depth_first_search_recursive(graph, 'A'))
# Ausgabe: ['A', 'B', 'D', 'E', 'F', 'C']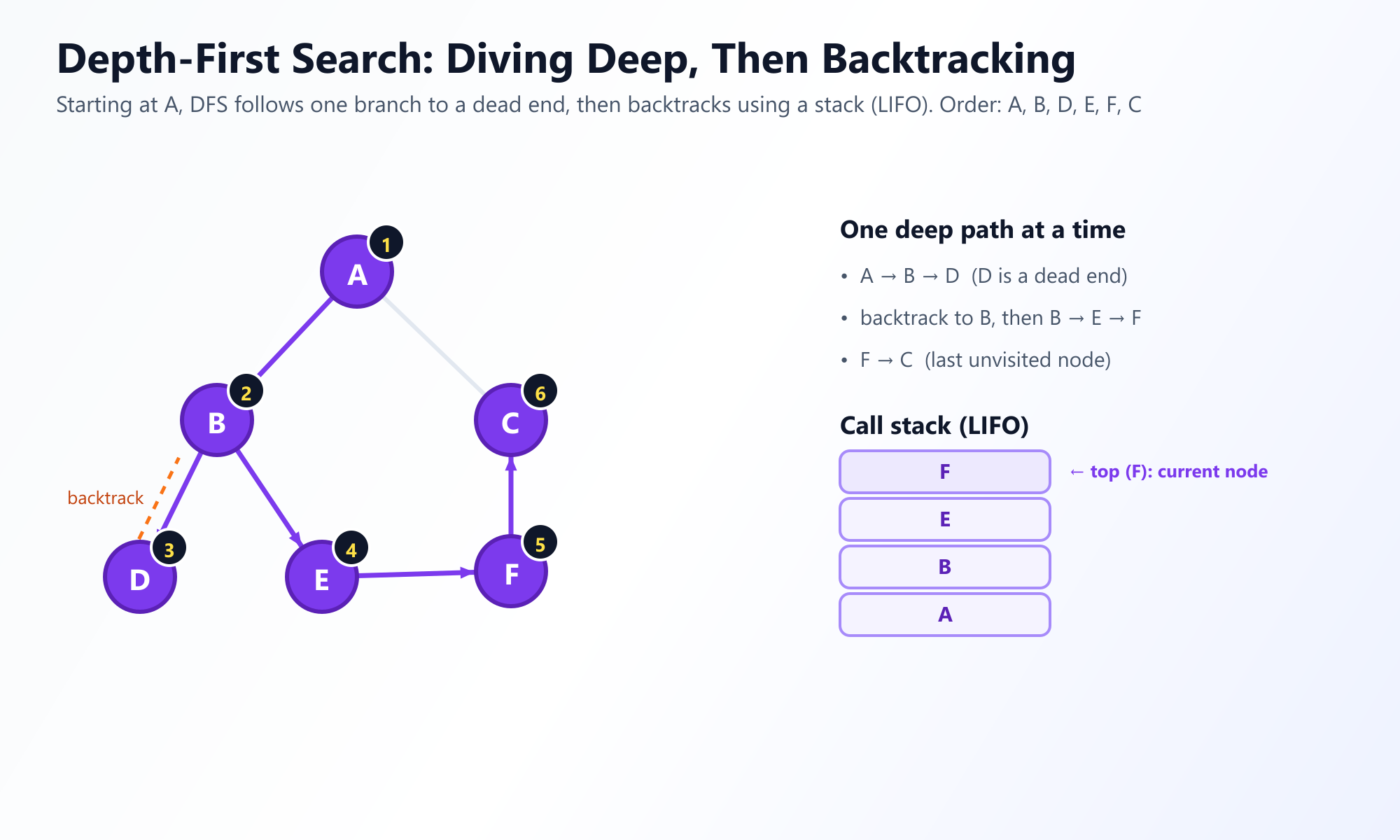
Beachten Sie den Unterschied in der Ausgabe im Vergleich zu BFS. DFS verfolgte aggressiv den Pfad A nach B nach D, bevor es zurückverfolgte.
Visualisieren Sie die Magie des Backtrackings
Rekursive Aufrufstapel können schwer im Kopf abzubilden sein. Sehen Sie, wie DFS tief eintaucht und die Kanten visuell zurückverfolgt, wenn es stecken bleibt.
Interaktiven DFS-Visualisierer starten3. BFS vs. DFS: Der ultimative Vergleich
Bei technischen Vorstellungsgesprächen und realem Systemdesign kann die Wahl des falschen Durchsuchungsalgorithmus zu katastrophaler Speichererschöpfung oder hocheffizienten Ausführungszeiten führen. Lassen Sie uns die technischen Unterschiede aufschlüsseln.
| Metrik | Breitensuche (BFS) | Tiefensuche (DFS) |
|---|---|---|
| Datenstruktur | Warteschlange (FIFO) - Iterativer Ansatz | Stapel (LIFO) - Oft rekursiver Ansatz |
| Zeitkomplexität | O(V + E)Muss jeden Knoten (V) besuchen und jede Kante (E) überprüfen. |
O(V + E)Besucht ebenfalls jeden Knoten und erkundet jede Kante. |
| Platzkomplexität | O(W) wobei W die maximale Breite des Graphen ist.Kann in Worst-Case-dichten Graphen O(V) sein. |
O(H) wobei H die maximale Tiefe/Höhe des Graphen ist.Kann O(V) sein, wenn der Graph eine einzige lange Linie ist. |
| Garantie für den kürzesten Weg | Ja. Für ungewichtete Graphen findet BFS garantiert den kürzesten Weg. | Nein. DFS findet möglicherweise einen sehr verschlungenen, massiven Pfad vor dem kurzen, direkten. |
| Speicherbedarf | Hoch, wenn der Baum/Graph sehr breit ist (z. B. soziales Netzwerk). Die Warteschlange muss alle Knoten der aktuellen Ebene halten. | Hoch, wenn der Baum/Graph sehr tief ist. Der Aufrufstapel muss alle Vorfahren des aktuellen Knotens halten. |
| Optimalität | Optimal für das Finden von Zielen in der Nähe der Quelle. | Optimal für das Finden von Zielen weit weg von der Quelle oder das Erkunden aller Möglichkeiten. |
Verstehen des Platzkomplexitäts-Trade-offs
Während beide Algorithmen eine Zeitkomplexität von O(V + E) haben, unterscheiden sich ihre Platzkomplexitäten je nach Topologie des Graphen drastisch.
- Breite Graphen: Wenn ein Graph einen massiven Verzweigungsfaktor hat (z. B. ein HTML-DOM-Baum oder ein Twitter-Follower-Graph), wird die BFS-Warteschlange in ihrer Größe anschwellen, da sie eine gesamte "Ebene" des Graphen auf einmal speichern muss. In diesen Szenarien ist DFS sehr speichereffizient.
- Tiefe Graphen: Wenn ein Graph extrem tief ist (z. B. eine massive Blockchain oder ein tiefer Entscheidungsbaum), überschreitet DFS möglicherweise die maximale Rekursionstiefe oder verbraucht zu viel Stapelspeicher. In diesen Szenarien könnte BFS vorzuziehen sein, obwohl die iterative Vertiefung DFS oft die in der Produktion verwendete Lösung ist.
4. Reale Anwendungen: Wann ist was zu verwenden?
Die Wahl zwischen BFS und DFS hängt normalerweise davon ab, was Sie aus der Graphenstruktur extrahieren möchten.
Verwenden Sie Breitensuche, wenn:
- Finden des kürzesten Weges (Ungewichtete Graphen): Da BFS Ebene für Ebene erkundet, hat es bei der ersten Begegnung mit dem Zielknoten definitiv die wenigsten Kanten genommen, um dorthin zu gelangen. GPS-Routing-Algorithmen verwenden aus diesem Grund oft Variationen von BFS (wie Dijkstra).
- Ziel ist wahrscheinlich in der Nähe der Quelle: Wenn Sie einen Stammbaum nach einem unmittelbaren Cousin durchsuchen, wird BFS ihn sofort finden. DFS könnte einen völlig anderen Zweig der Familie bis ins 16. Jahrhundert durchsuchen, bevor der Cousin überprüft wird.
- Peer-to-Peer-Netzwerke: Protokolle wie BitTorrent verwenden BFS, um Nachbarknoten zu finden. "Finde alle Peers 1 Hop entfernt, dann 2 Hops entfernt."
- Webcrawler: Suchmaschinen wie Google verwendeten ursprünglich BFS, um das Web zu crawlen. Sie möchten die prominentesten Links auf der Hauptseite indizieren, bevor sie tief in obskure, verschachtelte Unterseiten eintauchen.
- "Trennungsgrade" in sozialen Netzwerken: Funktionen wie die "Verbindung 2. Grades" bei LinkedIn basieren vollständig auf BFS-Limits.
Verwenden Sie Tiefensuche, wenn:
- Prüfen auf Zyklen: DFS ist einzigartig gerüstet, um Rückkanten (Kanten, die auf einen Vorfahren zurückweisen) zu finden. Wenn eine Rückkante existiert, hat der Graph einen Zyklus. Dies ist entscheidend, um Endlosschleifen in Routern zu verhindern und Deadlocks in Betriebssystemen zu erkennen.
- Topologisches Sortieren: In Build-Systemen (wie Make, Webpack oder npm) haben Aufgaben Abhängigkeiten. DFS wird verwendet, um diese Aufgaben linear zu ordnen, sodass jede Aufgabe erst ausgeführt wird, nachdem ihre Abhängigkeiten erfüllt sind.
- Speicher ist stark eingeschränkt (und der Graph ist breit): Wie besprochen, muss DFS nur den Pfad von der Wurzel zum aktuellen Knoten speichern, was es unglaublich speichereffizient für breite, massive Graphen wie Spielzustandsbäume (z. B. Schach-Engines) macht.
- Rätsel und Labyrinthe lösen: DFS ist der Algorithmus der Wahl zum Lösen von Sudoku, N-Damen-Problemen oder zum Erstellen/Lösen physischer Labyrinthe. Er erkundet aggressiv eine mögliche Lösung, und wenn sie fehlschlägt, macht er einfach einen Rückzieher und versucht die nächste Konfiguration.
- Finden stark zusammenhängender Komponenten: Algorithmen wie die von Tarjan oder Kosaraju stützen sich stark auf DFS, um Knoten in stark zusammenhängenden Clustern zu gruppieren.
5. Fortgeschrittene Variationen
In der modernen Informatik werden rohes BFS und rohes DFS oft erweitert, um massive Skalen zu bewältigen.
- Bidirektionales BFS: Anstatt BFS von der Quelle zum Ziel auszuführen, führen Sie zwei gleichzeitige BFS-Wellen aus - eine von der Quelle und eine vom Ziel. Wenn sich die Wellen schneiden, haben Sie den kürzesten Weg gefunden. Dies reduziert den Suchraumbereich drastisch.
- Iterative Vertiefung DFS (IDDFS): Dies kombiniert die Speichereffizienz von DFS mit der Garantie für den kürzesten Weg von BFS. Es führt eine DFS aus, legt aber ein striktes Tiefenlimit fest. Wenn das Ziel nicht gefunden wird, erhöht es das Tiefenlimit und beginnt von vorn. Es wird stark in der KI und der Spielbaumanalyse eingesetzt.
Fazit
Breitensuche und Tiefensuche sind die unbestrittenen Eckpfeiler der Graphentheorie. BFS ist Ihre ausgedehnte, ebenenweise Welle, perfekt für kürzeste Wege und breite Netzwerkanalysen. DFS ist Ihr aggressiver, speichereffizienter Labyrinthläufer, perfekt für Zykluserkennung, topologisches Sortieren und tiefe Rätsellösung.
Die Beherrschung beider Algorithmen ist nicht verhandelbar, um technische Vorstellungsgespräche bei Top-Tech-Unternehmen zu bestehen und robuste, skalierbare Softwarearchitekturen zu entwerfen.
Häufig gestellte Fragen
Wann sollte ich BFS statt DFS wählen?
Wählen Sie die Breitensuche (BFS) zur Suche des kürzesten Pfads in ungewichteten Graphen oder wenn das Ziel nah am Startknoten liegt.
Wann ist DFS vorteilhafter als BFS?
Die Tiefensuche (DFS) ist besser zum Erkunden aller Möglichkeiten (z. B. Labyrinthe), für topologische Sortierung, Zyklenerkennung oder bei Speichereinschränkungen.
Welche Datenstrukturen nutzen BFS und DFS?
BFS nutzt eine Warteschlange (Queue, FIFO) zur ebenenweisen Suche. DFS nutzt einen Stapelspeicher (Stack, LIFO), oft implizit über Rekursion realisiert.