
Table des Matières
Le parcours de graphe est le mécanisme fondamental de presque tous les algorithmes de la théorie des graphes. C'est le processus systématique de visite, de vérification, d'analyse et souvent de mise à jour de chaque sommet (nœud) dans un graphe. Que vous cherchiez l'itinéraire le plus court sur Google Maps, recommandiez des amis sur un réseau social, indexiez Internet pour un moteur de recherche ou résolviez un puzzle complexe de manière algorithmique, vous utilisez le parcours de graphe.
Au cœur de ce domaine se trouvent deux algorithmes légendaires : la Recherche en Largeur (Breadth-First Search, BFS) et la Recherche en Profondeur (Depth-First Search, DFS). Bien que les deux garantissent que chaque nœud accessible dans une composante connexe sera visité exactement une fois, l'ordre et la stratégie par lesquels ils visitent les nœuds conduisent à des applications, des complexités temporelles/spatiales et des comportements drastiquement différents.
Dans ce guide complet, nous allons décortiquer les deux algorithmes, examiner leurs structures de données, passer en revue le code d'implémentation, comparer leurs complexités et enfin examiner des scénarios réels pour vous aider à répondre avec confiance à la question ultime : "Quand dois-je utiliser BFS et quand DFS ?"
1. Plongée dans la recherche en largeur (BFS)
La recherche en largeur explore le graphe par "ondes" concentriques. Elle commence à un nœud racine choisi (ou tout nœud de départ) et visite d'abord tous ses voisins immédiats. Ce n'est qu'après avoir complètement épuisé tous les nœuds à une distance d'exactement 1 arête qu'elle passe aux nœuds à une distance de 2, et ainsi de suite.
L'analogie de la goutte d'eau : Pensez à BFS comme à une goutte d'eau créant des ondulations dans un étang immobile. L'ondulation s'étend vers l'extérieur uniformément dans toutes les directions. Elle ne part pas en ligne droite ; elle couvre la zone uniformément par rayon.
La mécanique de BFS
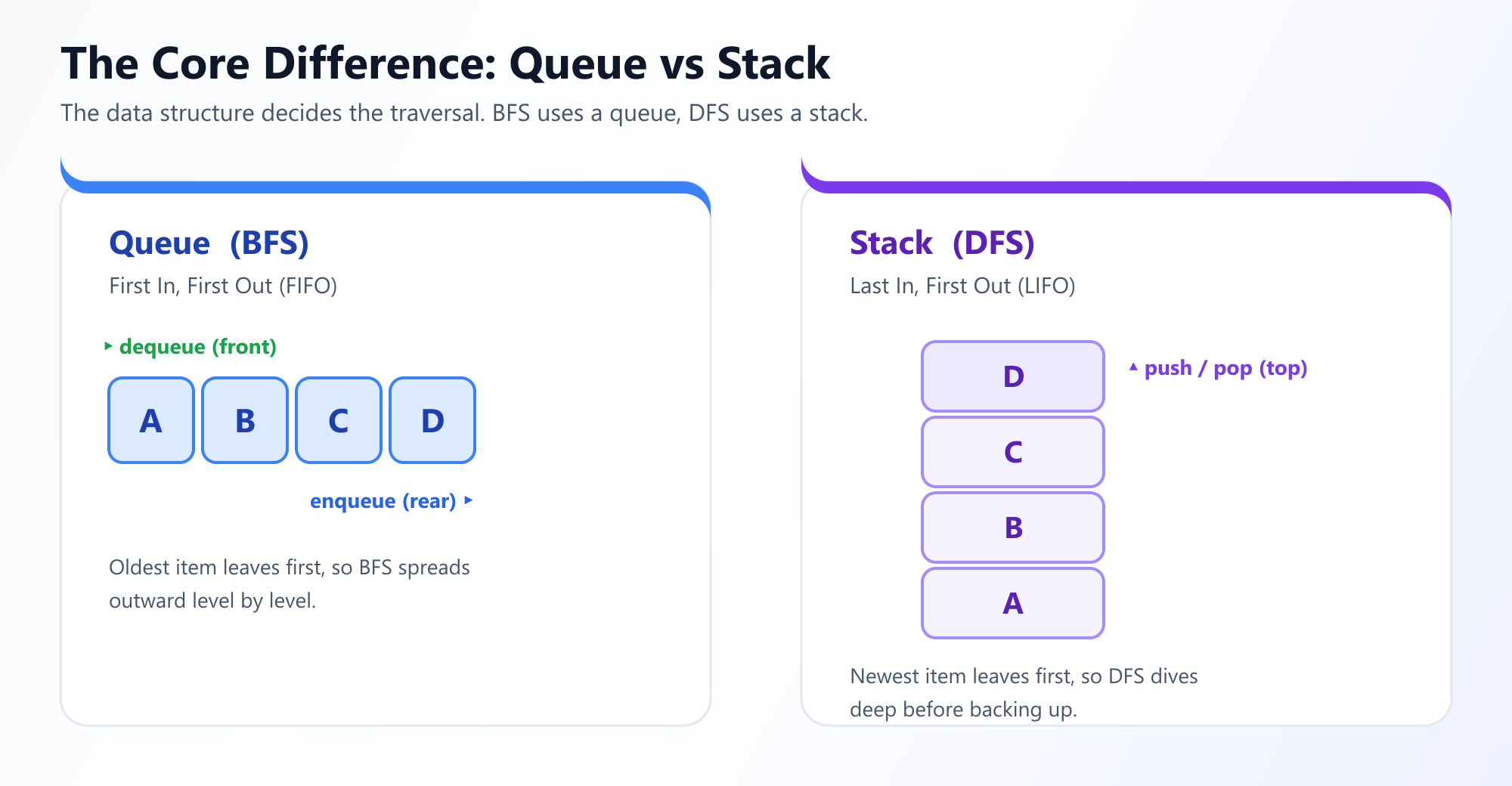
Pour s'assurer que les nœuds sont visités strictement couche par couche, BFS s'appuie sur une File (Queue) (First-In, First-Out, ou FIFO) pour garder une trace des nœuds à visiter ensuite.
L'algorithme BFS standard suit ces étapes :
- Initialiser une File et un tableau booléen (ou un Hash Set) pour garder une trace des nœuds
visités. - Ajouter le nœud de départ à la file et le marquer immédiatement comme
visité. - Commencer une boucle qui continue tant que la File n'est pas vide.
- Retirer le nœud à l'avant de la file. C'est votre nœud actuel. Traitez-le comme vous le souhaitez.
- Itérer sur chaque voisin adjacent de ce nœud actuel.
- Si un voisin n'a pas encore été visité, marquez-le comme
visitéet ajoutez-le à la file. - Répétez jusqu'à ce que la File soit vide.
Exemple d'implémentation BFS
Vous trouverez ci-dessous une implémentation propre de BFS en Python utilisant une représentation par liste d'adjacence et la très efficace collections.deque.
from collections import deque
def breadth_first_search(graph, start_node):
# Initialise une file et un ensemble pour les nœuds visités
queue = deque([start_node])
visited = {start_node}
# Stocke l'ordre de parcours
traversal_order = []
while queue:
# Retire le nœud à l'avant de la file
current_node = queue.popleft()
traversal_order.append(current_node)
# Récupère tous les nœuds adjacents au nœud retiré
for neighbor in graph[current_node]:
if neighbor not in visited:
# Marque comme visité immédiatement AVANT d'ajouter à la file
# pour éviter les entrées en double dans la file
visited.add(neighbor)
queue.append(neighbor)
return traversal_order
# Graphe d'exemple (Liste d'adjacence)
graph = {
'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']
}
print(breadth_first_search(graph, 'A'))
# Sortie: ['A', 'B', 'C', 'D', 'E', 'F']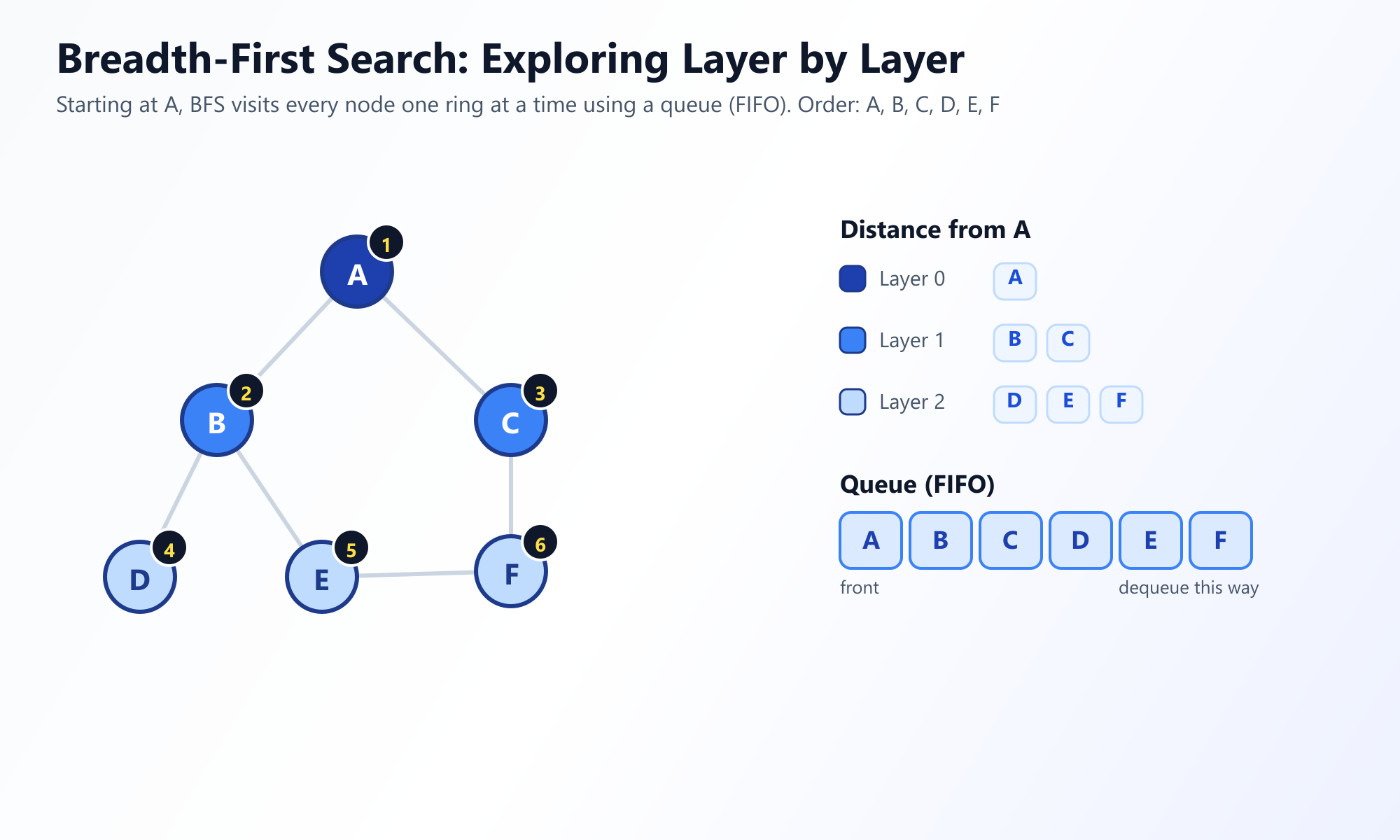
Arrêtez de lire, commencez à visualiser
Lire du code, c'est bien, mais regarder l'algorithme s'exécuter en temps réel construit une véritable intuition. Regardez comment la File gère l'onde BFS sur notre plateforme.
Lancer le visualiseur BFS interactif2. Plongée dans la recherche en profondeur (DFS)
La recherche en profondeur adopte une approche radicalement différente et plus agressive. Au lieu d'explorer largement, elle explore en profondeur. Elle commence par un nœud racine et explore aussi loin que possible le long d'une seule branche jusqu'à ce qu'elle atteigne une "impasse" (un nœud sans voisins non visités). Une fois bloquée, elle revient sur ses pas (backtracking) suffisamment haut sur le chemin pour trouver une nouvelle branche inexplorée à parcourir.
L'analogie du labyrinthe : Pensez à DFS comme à la navigation dans un labyrinthe physique. Vous placez votre main sur le mur de droite et vous continuez d'avancer. Vous prenez virage après virage jusqu'à ce que vous atteigniez une impasse. À ce stade, vous faites demi-tour, retournez à la dernière intersection et prenez le chemin inexploré.
La mécanique de DFS
Étant donné que DFS doit se rappeler d'où elle vient afin de pouvoir revenir en arrière, elle utilise une structure de données de type Pile (Stack) (Last-In, First-Out, ou LIFO). Généralement, les développeurs implémentent DFS de manière récursive, en exploitant élégamment la pile d'appels native du processeur au lieu de créer manuellement un objet Pile.
L'algorithme DFS récursif standard suit ces étapes :
- Commencer au nœud actuel et le marquer immédiatement comme
visité. - Traiter le nœud (par exemple, imprimer sa valeur).
- Itérer sur tous ses voisins adjacents.
- Si un voisin n'a pas été visité, appeler récursivement la fonction DFS sur ce voisin.
- Lorsque la boucle se termine (plus aucun voisin non visité), la fonction se termine, remontant automatiquement à l'appelant précédent dans la pile.
Exemple d'implémentation DFS
Vous trouverez ci-dessous une implémentation récursive élégante de DFS en Python.
def depth_first_search_recursive(graph, current_node, visited=None, traversal_order=None):
# Initialiser les collections lors du premier appel
if visited is None:
visited = set()
if traversal_order is None:
traversal_order = []
# Marquer le nœud actuel comme visité et l'enregistrer
visited.add(current_node)
traversal_order.append(current_node)
# Visiter récursivement tous les voisins non visités
for neighbor in graph[current_node]:
if neighbor not in visited:
depth_first_search_recursive(graph, neighbor, visited, traversal_order)
return traversal_order
# Graphe d'exemple (Liste d'adjacence)
graph = {
'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']
}
print(depth_first_search_recursive(graph, 'A'))
# Sortie: ['A', 'B', 'D', 'E', 'F', 'C']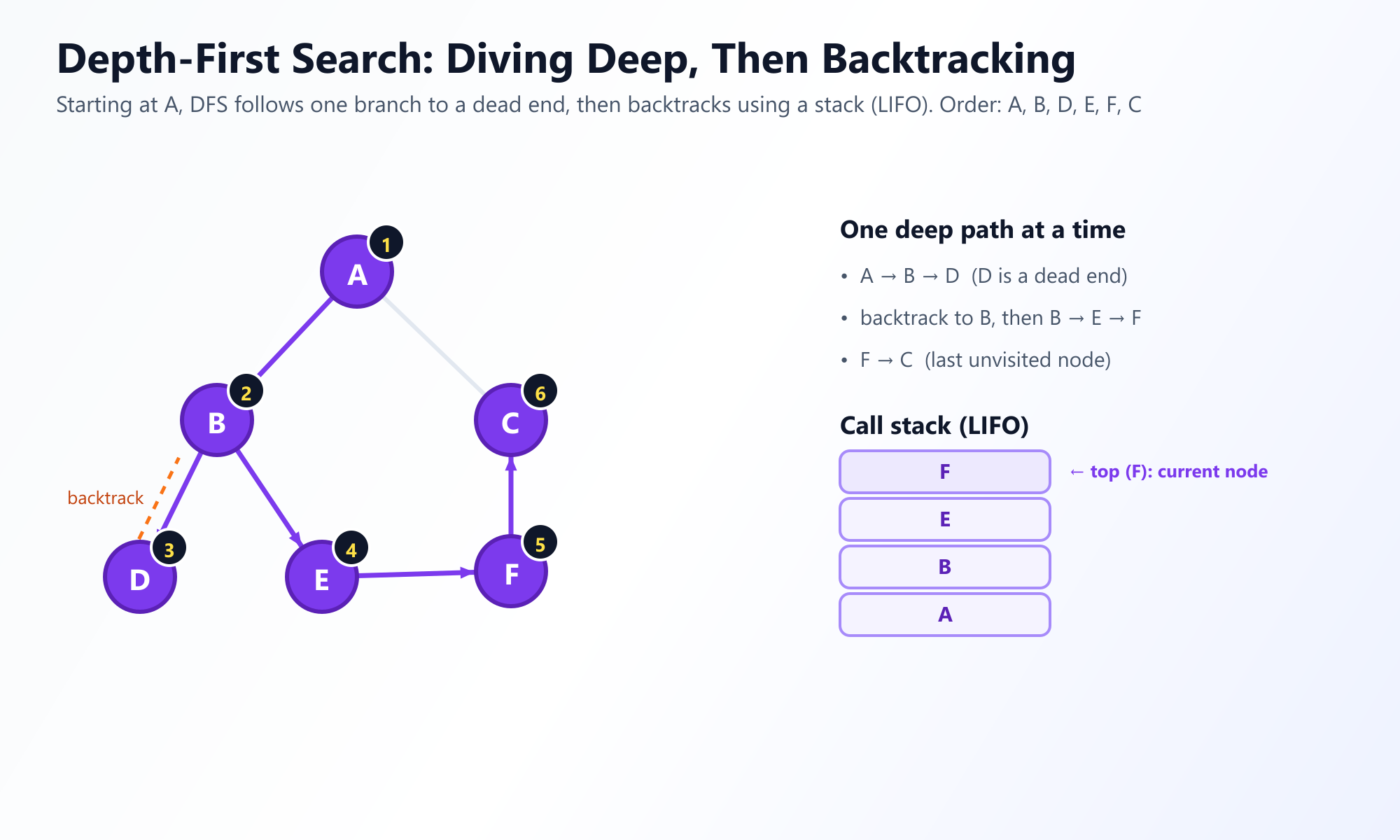
Notez la différence de sortie par rapport à BFS. DFS a suivi agressivement le chemin de A à B puis D avant de revenir en arrière.
Visualisez la magie du Backtracking
Les piles d'appels récursifs peuvent être difficiles à visualiser mentalement. Observez comment DFS plonge et revient visuellement sur ses pas lorsqu'il est bloqué.
Lancer le visualiseur DFS interactif3. BFS vs. DFS : La comparaison ultime
Lors d'entretiens techniques et de conception de systèmes réels, choisir le mauvais algorithme de parcours peut entraîner un épuisement catastrophique de la mémoire ou des temps d'exécution très inefficaces. Analysons les différences techniques.
| Métrique | Recherche en Largeur (BFS) | Recherche en Profondeur (DFS) |
|---|---|---|
| Structure de Données | File (FIFO) - Approche Itérative | Pile (LIFO) - Souvent Approche Récursive |
| Complexité Temporelle | O(V + E)Doit visiter chaque Sommet et vérifier chaque Arête. |
O(V + E)Visite également chaque Sommet et explore chaque Arête. |
| Complexité Spatiale | O(W) où W est la largeur maximale du graphe.Peut être O(V) dans les graphes denses dans le pire des cas. |
O(H) où H est la profondeur/hauteur maximale du graphe.Peut être O(V) si le graphe est une seule longue ligne. |
| Garantie du chemin le plus court | Oui. Pour les graphes non pondérés, BFS garantit de trouver le chemin le plus court. | Non. DFS pourrait trouver un chemin massif et alambiqué avant le chemin court et direct. |
| Surcharge de mémoire | Élevée si l'arbre/graphe est très large (ex. réseau social). La file doit contenir tous les nœuds du niveau actuel. | Élevée si l'arbre/graphe est très profond. La pile d'appels doit contenir tous les ancêtres du nœud actuel. |
| Optimalité | Optimal pour trouver des cibles proches de la source. | Optimal pour trouver des cibles loin de la source ou explorer toutes les possibilités. |
Comprendre le compromis de la complexité spatiale
Bien que les deux algorithmes partagent une complexité temporelle de O(V + E), leurs complexités spatiales diffèrent considérablement selon la topologie du graphe.
- Graphes Larges : Si un graphe a un facteur de ramification massif (comme un arbre DOM HTML ou un graphe d'abonnés Twitter), la file BFS grossira considérablement car elle doit stocker tout un "niveau" du graphe à la fois. Dans ces scénarios, DFS est très efficace en mémoire.
- Graphes Profonds : Si un graphe est extrêmement profond (comme une blockchain massive ou un arbre de décision profond), DFS pourrait dépasser la profondeur maximale de récursivité ou consommer trop de mémoire de pile. Dans ces scénarios, BFS pourrait être préférable, bien que l'approfondissement itératif DFS soit souvent la solution utilisée en production.
4. Applications dans le monde réel : Quand utiliser quoi ?
Le choix entre BFS et DFS se résume généralement à ce que vous essayez d'extraire de la structure du graphe.
Utilisez la recherche en largeur (BFS) quand :
- Trouver le chemin le plus court (Graphes non pondérés) : Parce que BFS explore niveau par niveau, la première fois qu'il rencontre le nœud cible, il a définitivement pris le moins d'arêtes pour y arriver. Les algorithmes de routage GPS utilisent souvent des variations de BFS (comme Dijkstra) pour cette raison même.
- La cible est probablement proche de la source : Si vous recherchez un cousin germain dans un arbre généalogique, BFS le trouvera immédiatement. DFS pourrait explorer une branche complètement différente de la famille jusqu'au 16ème siècle avant de vérifier ce cousin.
- Réseaux Peer-to-Peer : Des protocoles comme BitTorrent utilisent BFS pour trouver des nœuds voisins. "Trouve tous les pairs à 1 saut, puis à 2 sauts."
- Crawlers Web : Les moteurs de recherche comme Google utilisaient à l'origine BFS pour explorer le web. Vous souhaitez indexer les liens les plus importants sur la page principale avant de plonger profondément dans des sous-pages obscures et imbriquées.
- "Degrés de séparation" sur les réseaux sociaux : Des fonctionnalités comme la "connexion au 2ème degré" de LinkedIn s'appuient entièrement sur des limites BFS.
Utilisez la recherche en profondeur (DFS) quand :
- Vérifier les cycles : DFS est particulièrement bien équipé pour trouver des arêtes arrière (arêtes pointant vers un ancêtre). Si une arête arrière existe, le graphe a un cycle. Ceci est essentiel pour éviter les boucles infinies dans les routeurs et détecter les blocages (deadlocks) dans les systèmes d'exploitation.
- Tri topologique : Dans les systèmes de construction (comme Make, Webpack ou npm), les tâches ont des dépendances. DFS est utilisé pour ordonner linéairement ces tâches de sorte que chaque tâche s'exécute uniquement après que ses dépendances sont satisfaites.
- La mémoire est très limitée (et le graphe est large) : Comme discuté, DFS n'a besoin de stocker que le chemin de la racine au nœud actuel, ce qui le rend incroyablement efficace en mémoire pour les graphes larges et massifs comme les arbres d'état de jeu (ex. moteurs d'échecs).
- Résoudre des puzzles et des labyrinthes : DFS est l'algorithme de choix pour résoudre des Sudokus, le problème des N-Reines ou pour naviguer dans des labyrinthes physiques. Il explore agressivement une solution possible et si elle échoue, il revient simplement en arrière et essaie la configuration suivante.
- Trouver des composantes fortement connexes : Des algorithmes comme ceux de Tarjan ou Kosaraju s'appuient fortement sur DFS pour regrouper des nœuds en clusters fortement connectés.
5. Variations avancées
En informatique moderne, BFS et DFS de base sont souvent augmentés pour gérer des échelles massives.
- BFS Bidirectionnel : Au lieu d'exécuter BFS de la source à la destination, vous exécutez deux ondes BFS simultanées : une de la source et une de la destination. Lorsque les ondes se croisent, vous avez trouvé le chemin le plus court. Cela réduit considérablement l'espace de recherche.
- Approfondissement Itératif DFS (IDDFS) : Cela combine l'efficacité de la mémoire de DFS avec la garantie du chemin le plus court de BFS. Il exécute un DFS mais fixe une limite de profondeur stricte. Si la cible n'est pas trouvée, il augmente la limite de profondeur et recommence. Il est très utilisé dans l'Intelligence Artificielle et l'analyse d'arbres de jeux.
Conclusion
La recherche en largeur et la recherche en profondeur sont les pierres angulaires indiscutables de la théorie des graphes. BFS est votre onde expansive niveau par niveau, parfaite pour les chemins les plus courts et l'analyse de réseaux larges. DFS est votre explorateur de labyrinthe agressif et efficace en mémoire, parfait pour la détection de cycles, le tri topologique et la résolution de puzzles profonds.
Maîtriser ces deux algorithmes est non négociable pour réussir les entretiens techniques dans les grandes entreprises technologiques et concevoir des architectures logicielles robustes et évolutives.
Foire aux questions
Quand choisir le BFS plutôt que le DFS ?
Choisissez le BFS (parcours en largeur) pour trouver le chemin le plus court dans un graphe non pondéré, ou lorsque le nœud recherché est proche du point de départ.
Quand le DFS est-il préférable au BFS ?
Le DFS (parcours en profondeur) est idéal pour explorer toutes les possibilités (ex. labyrinthes), trier les dépendances (tri topologique) ou en cas de mémoire limitée.
Quelles structures de données utilisent-ils ?
Le BFS utilise une file d'attente (FIFO) pour explorer niveau par niveau. Le DFS utilise une pile (LIFO), souvent gérée via la récursivité.