
目录
1. 什么是最小生成树 (MST)?
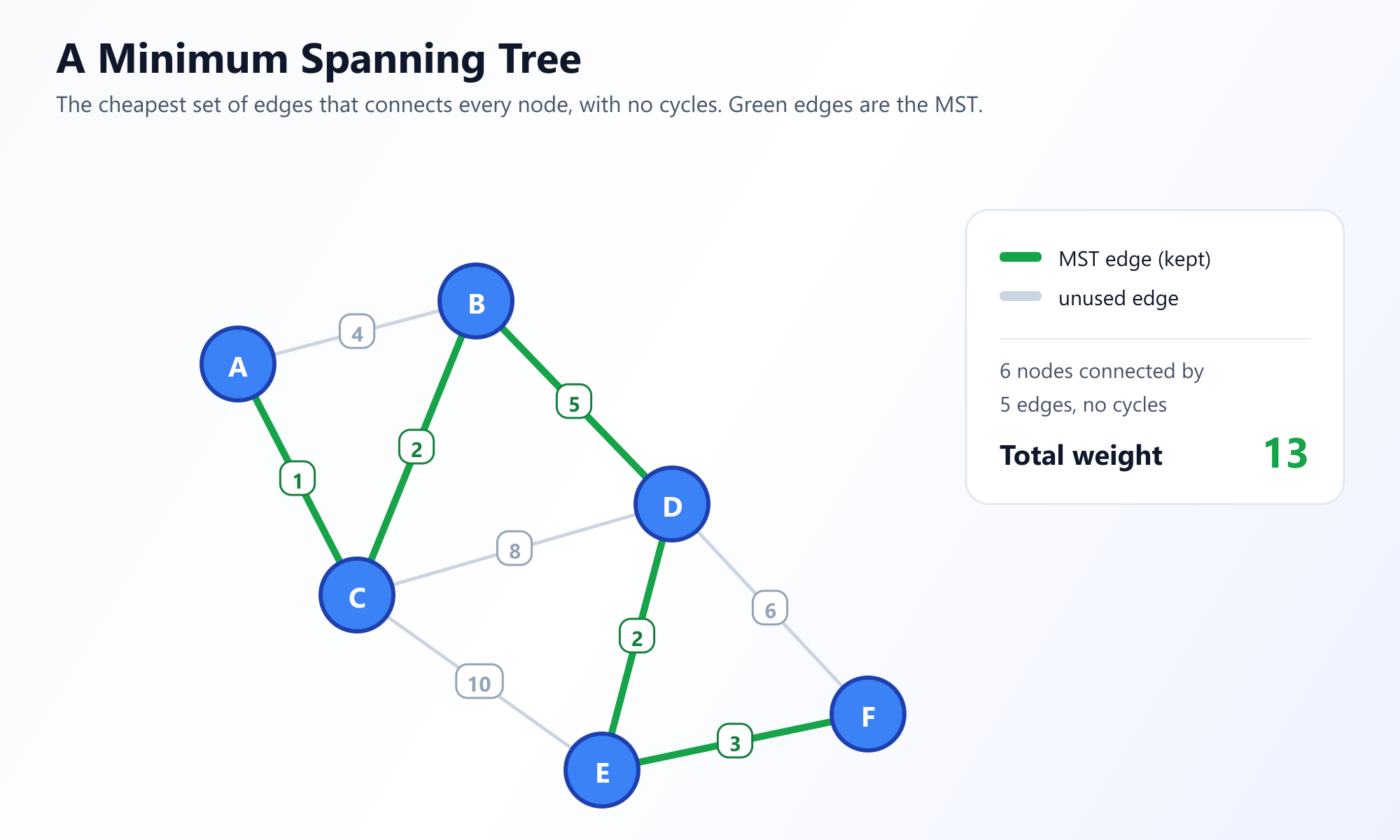
想象一下,你的任务是为一座城市设计一个新的电信网络。你有一张地图,上面有几个街区(节点)和你可以铺设光纤电缆的可能路线(边)。铺设电缆很昂贵,而且成本因地形而异(边权重)。
你的目标是确保 每个 街区都连接到网络,这意味着从任何街区到任何其他街区都有路径。然而,为了省钱,你希望 铺设电缆的总成本 尽可能小。你不需要多余的连接;只要所有东西都连在一起,你就满意了。
这种确切的场景就是 最小生成树 (Minimum Spanning Tree, MST) 问题的教科书式定义。
让我们分解一下术语:
- 树 (Tree): 一个绝对没有环的连通图。如果你有
V个顶点,一棵树将始终只有V - 1条边。 - 生成 (Spanning): 它覆盖(跨越)原始图中的每一个顶点。
- 最小 (Minimum): 在可以在图上绘制的所有可能的生成树中,这一棵的边权重总和最小。
需要注意的是,如果多条边具有相同的权重,一个图可能有多个最小生成树,但 最小总权重 始终是唯一的。
为了解决这个问题,计算机科学严重依赖于两个传奇的贪心算法:Prim 算法 和 Kruskal 算法。
2. Prim 算法:以节点为中心的方法
Prim 算法最初由数学家 Vojtěch Jarník 在 1930 年设计,后来由 Robert Prim 在 1957 年重新发现并推广。Prim 采用 以节点为中心 的方法,从单个起始顶点慢慢向外生长这棵树,就像霉菌在面包片上蔓延一样。
策略: 从任意节点开始。查看连接你当前不断增长的树中的节点与树外节点的所有边。选择权重最低的边。将该边和新节点添加到你的树中。重复此过程,直到包含所有节点。
工作机制
为了有效地找到连接树与外部世界的权重最低的边,Prim 算法大量使用了 优先队列 (Priority Queue, 最小堆),这使得它在结构上与 Dijkstra 最短路径算法非常相似。
- 初始化一个布尔数组,以跟踪已包含在 MST 中的节点。
- 初始化一个优先队列来存储
(边权重, 目标节点)的元组。 - 随机选择一个起始节点,将其标记为已包含,并将其所有边推入优先队列。
- 当优先队列不为空且 MST 的边数不到
V - 1时: - 弹出具有最小权重的边。
- 如果目标节点 已经 在 MST 中,则忽略它(以防止出现环)。
- 否则,将该边添加到 MST,将新节点标记为已包含,并将从这个新节点辐射出来的所有边推入优先队列。
Python 中的 Prim 算法
import heapq
def prims_algorithm(graph, start_node):
# 图表示为邻接表:
# graph[u] = [(权重, v), ...]
mst = []
visited = set([start_node])
# 用起始节点的边初始化优先队列
edges = [ (权重, start_node, 目标节点) for 权重, 目标节点 in graph[start_node] ]
heapq.heapify(edges)
total_cost = 0
while edges:
权重, 起点, 终点 = heapq.heappop(edges)
# 如果目标节点未被访问,则它是一条安全边
if 终点 not in visited:
visited.add(终点)
mst.append((起点, 终点, 权重))
total_cost += 权重
# 推入源自新访问节点的所有边
for 下一个权重, 下一个终点 in graph[终点]:
if 下一个终点 not in visited:
heapq.heappush(edges, (下一个权重, 终点, 下一个终点))
return mst, total_cost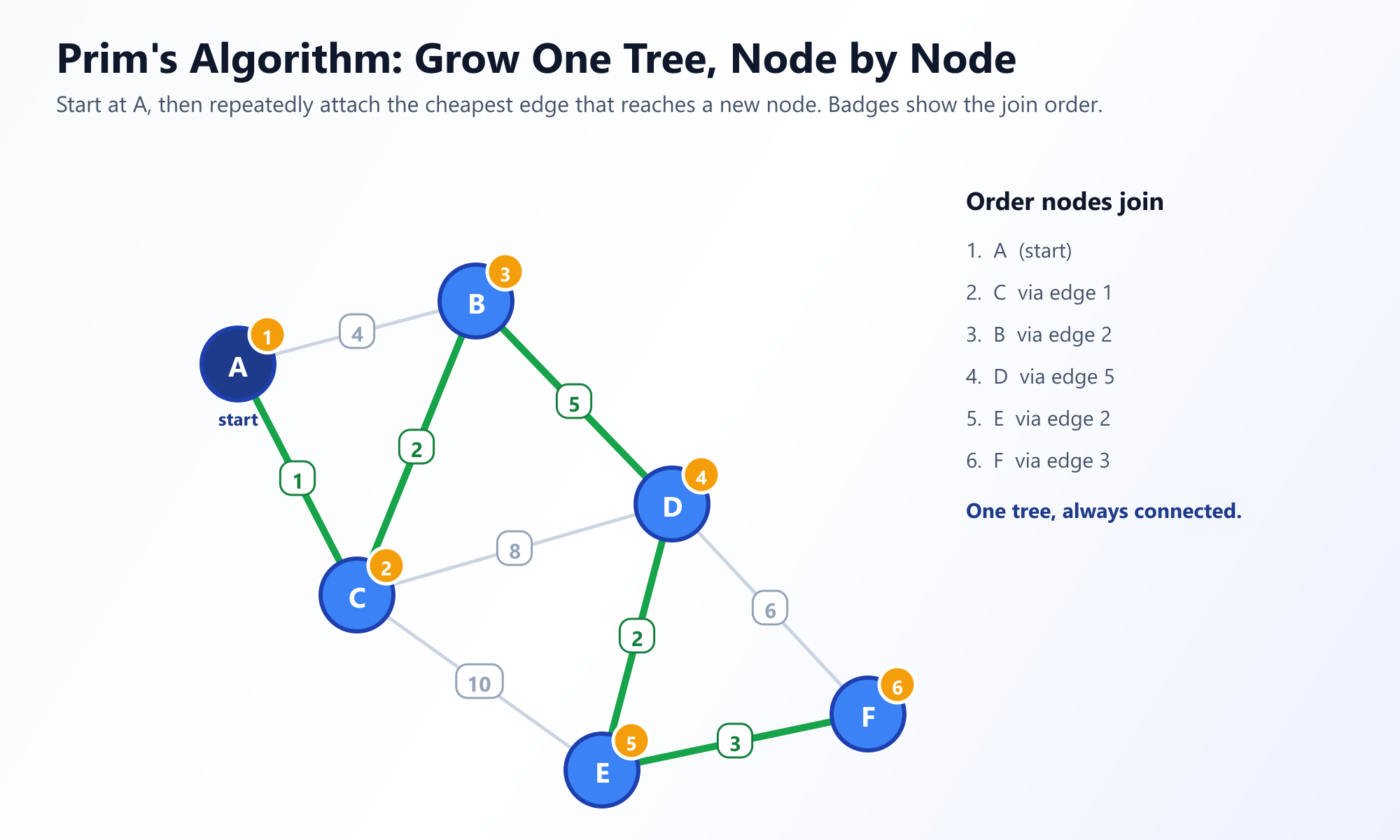
3. Kruskal 算法:以边为中心的方法
Joseph Kruskal 在 1956 年发表了他的算法。与 Prim 从一个根生长出一棵连续的树不同,Kruskal 采用的是 以边为中心 的方法。它将图视为一个整体,完全专注于边而不是节点。
策略: 将所有的边放在一堆,并按权重从小到大排序。拿起最小的边。如果将这条边添加到你的 MST 中 不会 产生环,就保留它。如果它产生了一个环,就扔掉它。重复此过程,直到你有了 V - 1 条边。
最初,Kruskal 算法将每个节点视为一棵独立的树。随着它添加边,它将这些小树合并成更大的森林,直到最终,只有一棵覆盖整个图的巨大树。
4. 秘诀:并查集 (Union-Find)
Kruskal 算法的整个逻辑取决于一个关键步骤:“如果添加这条边不会产生环。”
我们如何才能有效地确定连接节点 A 和节点 B 是否会产生一个环?每次我们想要添加一条边时都运行一次完整的 DFS 会非常慢。这就是聪明的 并查集 (Union-Find) 数据结构发挥作用的地方。
并查集数据结构跟踪被划分为多个不相交(不重叠)子集的元素。它在接近恒定的 O(1) 时间内支持两个主要操作:
- 查找 (Find): 确定特定元素属于哪个集合。(通常通过找到集合的“根”或“代表”来实现)。
- 合并 (Union): 将两个子集合并(联合)成一个单一的子集。
在评估节点 A 和节点 B 之间的边时,我们只需调用 Find(A) 和 Find(B)。如果它们返回相同的根,则它们已经在同一个连通分量中,这意味着在它们之间添加边将创建一个环。如果它们返回不同的根,则添加该边是安全的,我们调用 Union(A, B)。
Python 中的 Kruskal 算法
class UnionFind:
def __init__(self, size):
# 最初,每个节点都是自己的父节点(根)
self.parent = [i for i in range(size)]
self.rank = [0] * size
def find(self, i):
# 路径压缩优化
if self.parent[i] == i:
return i
self.parent[i] = self.find(self.parent[i])
return self.parent[i]
def union(self, i, j):
root_i = self.find(i)
root_j = self.find(j)
if root_i != root_j:
# 按秩合并优化
if self.rank[root_i] < self.rank[root_j]:
self.parent[root_i] = root_j
elif self.rank[root_i] > self.rank[root_j]:
self.parent[root_j] = root_i
else:
self.parent[root_j] = root_i
self.rank[root_i] += 1
return True
return False
def kruskals_algorithm(vertices_count, edges):
# edges 是元组的列表:[(权重, u, v), ...]
# 步骤 1:将所有边按权重的非递减顺序排序
edges.sort()
uf = UnionFind(vertices_count)
mst = []
total_cost = 0
# 步骤 2:遍历已排序的边
for edge in edges:
权重, u, v = edge
# 如果包含这条边不会引起环,则包含它
if uf.union(u, v):
mst.append((u, v, 权重))
total_cost += 权重
# 优化:如果我们有 V-1 条边,则提前停止
if len(mst) == vertices_count - 1:
break
return mst, total_cost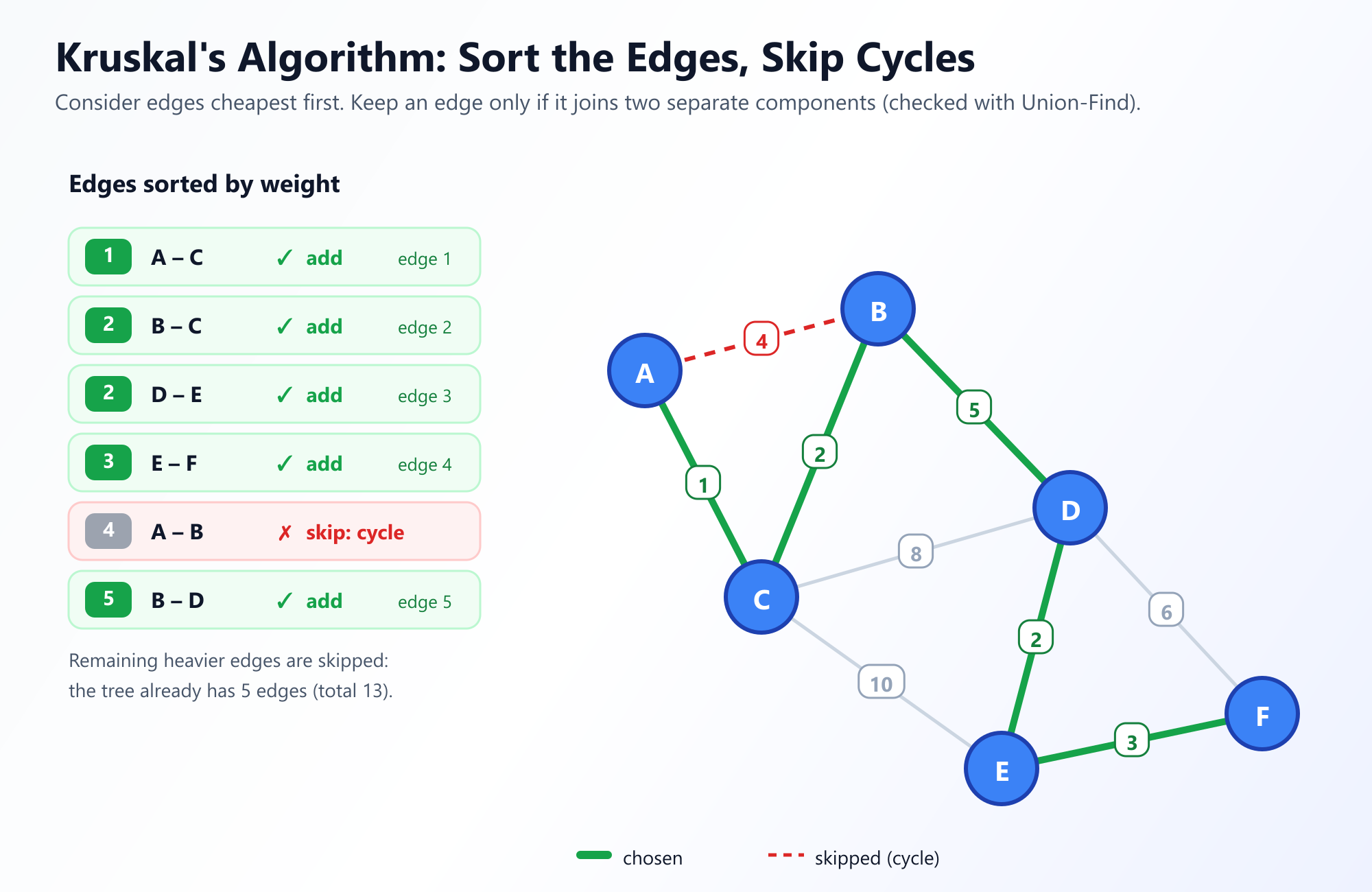
5. Prim vs. Kruskal:应该选择哪一个?
虽然这两种算法都能保证找到完全相同的最小生成树权重,但它们的性能会根据正在处理的图的拓扑结构而有显着差异。
| 指标 | Prim 算法 | Kruskal 算法 |
|---|---|---|
| 数据结构 | 优先队列 (Min-Heap) | 不相交集合 (Union-Find) |
| 时间复杂度 | 使用二叉堆时为 O(E log V)。 |
O(E log E) 或 O(E log V),很大程度上取决于对边进行排序。 |
| 图的密度 | 非常适合稠密图。 因为它只查看已访问节点的相邻边,当边数 E 接近 V² 时,它的性能要好得多。 |
非常适合稀疏图。 因为第一步是对所有边进行排序,边数较少会使排序速度极快。 |
| 实现复杂性 | 由于管理优先队列和跟踪访问状态,可能会稍微复杂一些。 | 非常容易实现,前提是您有一个预先写好的 Union-Find 类。 |
| 生长模式 | 长出一棵单一的、连续的树。 | 长出一片不相交的树林,最终合并在一起。 |
6. 现实世界中的应用
最小生成树不仅仅是一个理论构建;它在各种工程学科中被积极用于降低成本和优化布线。
- 网络设计: 电信、电网、供水网络和计算机网络使用 MST 算法来确保所有节点都以最少数量的物理电线或管道连接。
- 近似算法: MST 经常被用作解决更难的 NP 困难问题的垫脚石,例如旅行推销员问题 (TSP) 的近似求解。
- 聚类分析: 在机器学习和数据挖掘中,单链接聚类依赖于 Kruskal 算法,根据数据点到其他簇的最短距离来对其进行分组。
- 图像分割: MST 算法可用于根据像素相似性将图像划分为不同的区域或对象。
常见问题
什么是最小生成树 (MST)?
最小生成树是连通、带权的无向图的一个子图,它以无环的方式连接所有顶点,且所有边的权重之和最小。
并查集 (Union-Find) 是如何防止克鲁斯卡尔算法产生环的?
并查集用来追踪连通分量。在加入连接节点 u 和 v 的边之前,克鲁斯卡尔会检查它们是否在同一个集合中。如果是,说明它们已连通,加入该边会构成环,因此跳过。
一个图可以有多个最小生成树吗?
可以,如果图中存在多条相同权重的边。如果图中的所有边权都是唯一的,那么最小生成树也是唯一的。