
Inhaltsverzeichnis
- 1. Was ist ein minimaler Spannbaum?
- 2. Der Algorithmus von Prim: Der knotenzentrierte Ansatz
- 3. Der Algorithmus von Kruskal: Der kantenzentrierte Ansatz
- 4. Das Geheimrezept: Disjunkte Mengen (Union-Find)
- 5. Prim vs. Kruskal: Welchen soll man wählen?
- 6. Reale Anwendungen
- Häufig gestellte Fragen (FAQ)
1. Was ist ein minimaler Spannbaum (MST)?
Stellen Sie sich vor, Sie haben die Aufgabe, ein neues Telekommunikationsnetzwerk für eine Stadt zu entwerfen. Sie haben eine Karte mit mehreren Nachbarschaften (Knoten) und den möglichen Routen, auf denen Sie Glasfaserkabel verlegen können (Kanten). Das Verlegen von Kabeln ist teuer, und die Kosten variieren je nach Gelände (Kantengewichte).
Ihr Ziel ist es, sicherzustellen, dass jede Nachbarschaft an das Netzwerk angeschlossen ist, was bedeutet, dass es einen Pfad von jeder Nachbarschaft zu jeder anderen Nachbarschaft gibt. Um jedoch Geld zu sparen, möchten Sie, dass die Gesamtkosten für das Verlegen der Kabel so gering wie möglich sind. Sie benötigen keine redundanten Verbindungen; solange alles verbunden ist, sind Sie zufrieden.
Genau dieses Szenario ist die lehrbuchmäßige Definition des Minimalen Spannbaum (Minimum Spanning Tree, MST)-Problems.
Lassen Sie uns die Terminologie aufschlüsseln:
- Baum: Ein zusammenhängender Graph mit absolut keinen Zyklen. Wenn Sie
VKnoten haben, hat ein Baum immer genauV - 1Kanten. - Spannend: Er deckt (spannt) jeden einzelnen Knoten im ursprünglichen Graphen ab.
- Minimal: Unter allen möglichen Spannbäumen, die über dem Graphen gezeichnet werden könnten, hat dieser das geringste Gesamt-Kantengewicht.
Es ist wichtig zu beachten, dass ein Graph mehrere minimale Spannbäume haben kann, wenn mehrere Kanten die gleichen Gewichte haben, aber das minimale Gesamtgewicht wird immer eindeutig sein.
Um dieses Problem zu lösen, verlässt sich die Informatik stark auf zwei legendäre Greedy-Algorithmen (gierige Algorithmen): den Algorithmus von Prim und den Algorithmus von Kruskal.
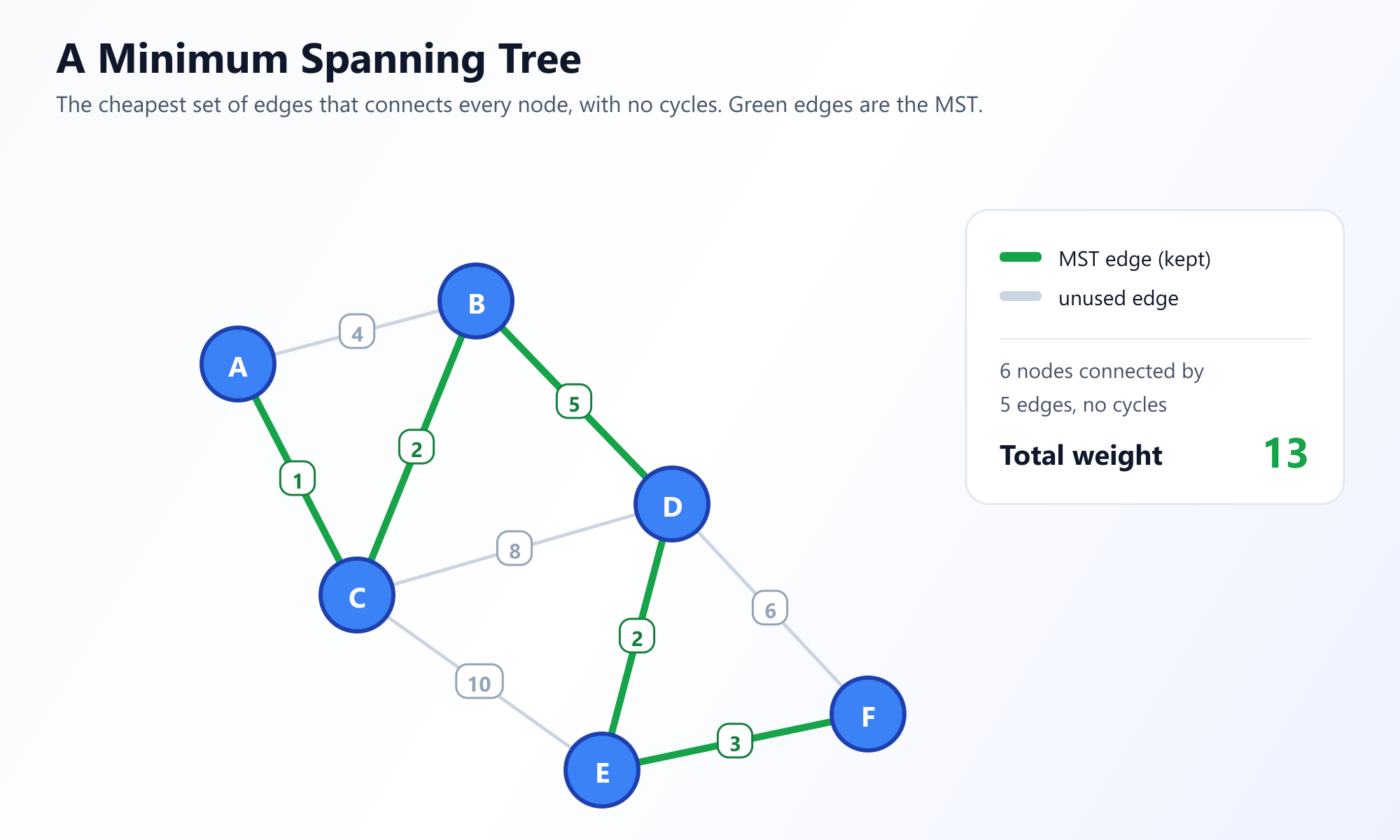
2. Der Algorithmus von Prim: Der knotenzentrierte Ansatz
Der Algorithmus von Prim wurde ursprünglich 1930 vom Mathematiker Vojtěch Jarník entwickelt und später 1957 von Robert Prim wiederentdeckt und populär gemacht. Prims Algorithmus verfolgt einen knotenzentrierten Ansatz und lässt den Baum langsam von einem einzigen Startknoten nach außen wachsen, ähnlich wie sich Schimmel auf einem Stück Brot ausbreitet.
Die Strategie: Beginnen Sie bei einem beliebigen Knoten. Betrachten Sie alle Kanten, die die Knoten in Ihrem aktuell wachsenden Baum mit Knoten außerhalb des Baums verbinden. Wählen Sie die Kante mit dem niedrigsten Gewicht. Fügen Sie diese Kante und den neuen Knoten zu Ihrem Baum hinzu. Wiederholen Sie dies, bis alle Knoten eingeschlossen sind.
Die Mechanik
Um die Kante mit dem niedrigsten Gewicht zu finden, die den Baum mit der Außenwelt verbindet, verwendet der Algorithmus von Prim intensiv eine Prioritätswarteschlange (Min-Heap), was ihn in seiner Struktur dem Dijkstra-Algorithmus für den kürzesten Weg sehr ähnlich macht.
- Initialisieren Sie ein boolesches Array, um zu verfolgen, welche Knoten bereits im MST enthalten sind.
- Initialisieren Sie eine Prioritätswarteschlange zum Speichern von Tupeln von
(Kantengewicht, Zielknoten). - Wählen Sie einen zufälligen Startknoten, markieren Sie ihn als enthalten und fügen Sie alle seine Kanten in die Prioritätswarteschlange ein.
- Solange die Prioritätswarteschlange nicht leer ist und der MST nicht
V - 1Kanten hat: - Entnehmen Sie die Kante mit dem minimalen Gewicht.
- Wenn der Zielknoten bereits im MST ist, ignorieren Sie ihn (um Zyklen zu vermeiden).
- Andernfalls fügen Sie die Kante zum MST hinzu, markieren den neuen Knoten als enthalten und fügen alle von diesem neuen Knoten ausgehenden Kanten in die Prioritätswarteschlange ein.
Der Algorithmus von Prim in Python
import heapq
def prims_algorithm(graph, start_node):
# graph wird als Adjazenzliste dargestellt:
# graph[u] = [(gewicht, v), ...]
mst = []
visited = set([start_node])
# Prioritätswarteschlange mit Kanten vom Startknoten initialisieren
edges = [ (gewicht, start_node, ziel_knoten) for gewicht, ziel_knoten in graph[start_node] ]
heapq.heapify(edges)
total_cost = 0
while edges:
gewicht, von, zu = heapq.heappop(edges)
# Wenn das Ziel nicht besucht ist, ist es eine sichere Kante
if zu not in visited:
visited.add(zu)
mst.append((von, zu, gewicht))
total_cost += gewicht
# Alle Kanten einfügen, die vom neu besuchten Knoten ausgehen
for naechstes_gewicht, naechstes_zu in graph[zu]:
if naechstes_zu not in visited:
heapq.heappush(edges, (naechstes_gewicht, zu, naechstes_zu))
return mst, total_cost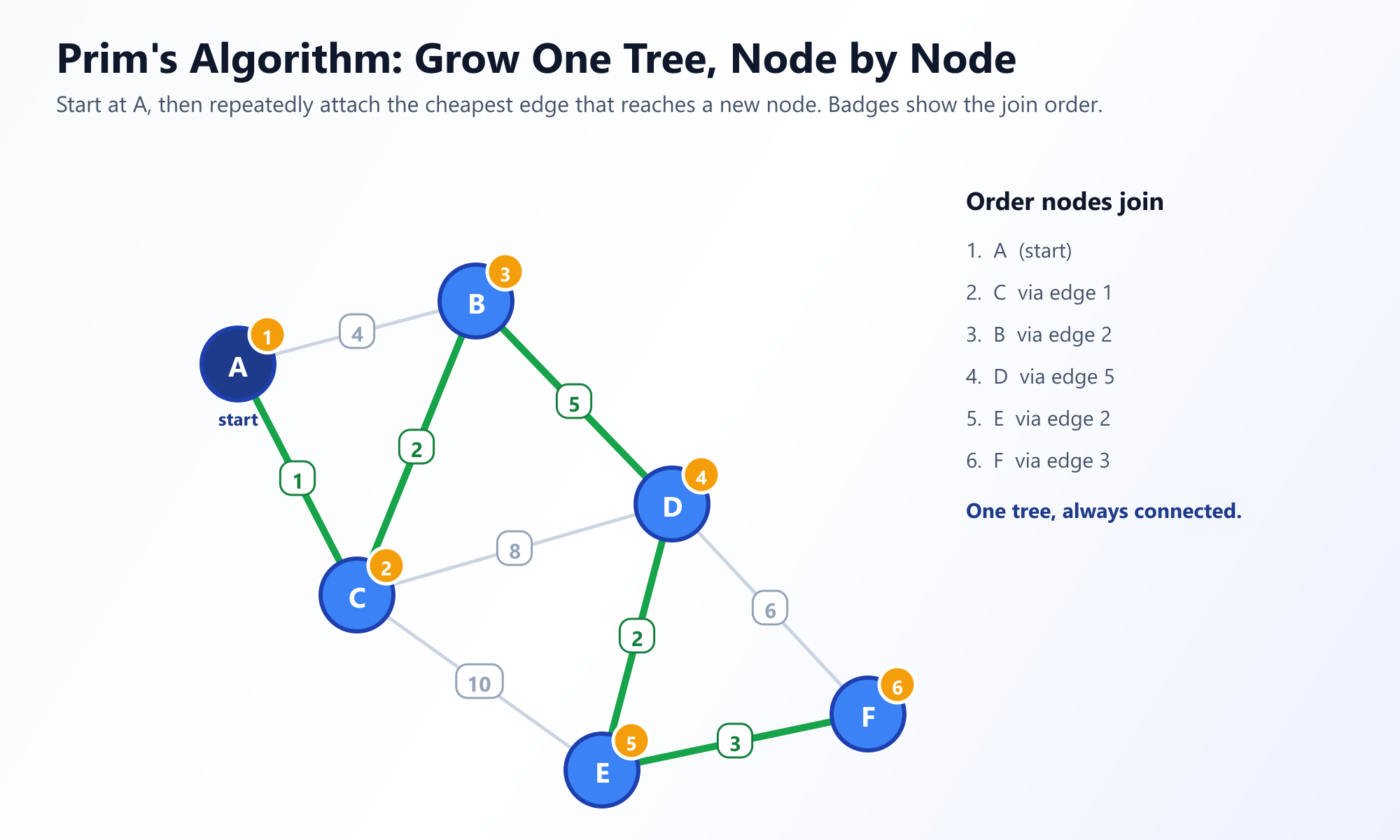
Visualisieren Sie das Wachstum von Prims Algorithmus
Beobachten Sie, wie die Prioritätswarteschlange die "Grenz"-Kanten in Echtzeit bewertet. Zu sehen, wie der Baum Knoten für Knoten wächst, ist der beste Weg, um die gierige Wahl zu verinnerlichen.
Starten Sie den interaktiven Prim-Visualisierer3. Der Algorithmus von Kruskal: Der kantenzentrierte Ansatz
Joseph Kruskal veröffentlichte seinen Algorithmus im Jahr 1956. Im Gegensatz zu Prim, der einen einzelnen zusammenhängenden Baum von einer Wurzel aus wachsen lässt, wählt Kruskal einen kantenzentrierten Ansatz. Er betrachtet den Graphen als Ganzes und konzentriert sich vollständig auf die Kanten und nicht auf die Knoten.
Die Strategie: Werfen Sie alle Kanten auf einen Haufen und sortieren Sie sie vom kleinsten zum größten Gewicht. Nehmen Sie die kleinste Kante. Wenn das Hinzufügen dieser Kante zu Ihrem MST keinen Zyklus erzeugt, behalten Sie sie. Wenn sie einen Zyklus erzeugt, werfen Sie sie weg. Wiederholen Sie dies, bis Sie V - 1 Kanten haben.
Anfänglich behandelt der Algorithmus von Kruskal jeden Knoten als seinen eigenen separaten Baum. Wenn er Kanten hinzufügt, verschmilzt er diese kleinen Bäume zu größeren Wäldern, bis es schließlich nur noch einen einzigen massiven Baum gibt, der den gesamten Graphen überspannt.
4. Das Geheimrezept: Disjunkte Mengen (Union-Find)
Die gesamte Logik von Kruskals Algorithmus hängt von einem entscheidenden Schritt ab: "Wenn das Hinzufügen dieser Kante keinen Zyklus erzeugt."
Wie können wir effizient feststellen, ob das Verbinden von Knoten A und Knoten B einen Zyklus erzeugt? Jedes Mal, wenn wir eine Kante hinzufügen möchten, eine vollständige Tiefensuche (DFS) durchzuführen, wäre schmerzhaft langsam. Hier kommt die brillante Datenstruktur der Disjunkten Menge (Union-Find) zur Rettung.
Eine Union-Find-Datenstruktur behält den Überblick über Elemente, die in eine Reihe von disjunkten (sich nicht überschneidenden) Teilmengen unterteilt sind. Sie unterstützt zwei primäre Operationen in nahezu konstanter O(1)-Zeit:
- Find: Bestimmen Sie, zu welcher Menge ein bestimmtes Element gehört. (Normalerweise durch Finden der "Wurzel" oder des "Repräsentanten" der Menge).
- Union: Verbinden (vereinen) Sie zwei Teilmengen zu einer einzigen Teilmenge.
Bei der Bewertung einer Kante zwischen Knoten A und Knoten B rufen wir einfach Find(A) und Find(B) auf. Wenn sie dieselbe Wurzel zurückgeben, befinden sie sich bereits in derselben verbundenen Komponente, was bedeutet, dass das Hinzufügen einer Kante zwischen ihnen einen Zyklus erzeugen würde. Wenn sie unterschiedliche Wurzeln zurückgeben, ist es sicher, die Kante hinzuzufügen, und wir rufen Union(A, B) auf.
Der Algorithmus von Kruskal in Python
class UnionFind:
def __init__(self, size):
# Anfänglich ist jeder Knoten sein eigener Elternteil (Wurzel)
self.parent = [i for i in range(size)]
self.rank = [0] * size
def find(self, i):
# Pfadkompressions-Optimierung
if self.parent[i] == i:
return i
self.parent[i] = self.find(self.parent[i])
return self.parent[i]
def union(self, i, j):
root_i = self.find(i)
root_j = self.find(j)
if root_i != root_j:
# Union-by-Rank-Optimierung
if self.rank[root_i] < self.rank[root_j]:
self.parent[root_i] = root_j
elif self.rank[root_i] > self.rank[root_j]:
self.parent[root_j] = root_i
else:
self.parent[root_j] = root_i
self.rank[root_i] += 1
return True
return False
def kruskals_algorithm(vertices_count, edges):
# edges ist eine Liste von Tupeln: [(gewicht, u, v), ...]
# Schritt 1: Sortiere alle Kanten in nicht-absteigender Reihenfolge ihres Gewichts
edges.sort()
uf = UnionFind(vertices_count)
mst = []
total_cost = 0
# Schritt 2: Iteriere durch die sortierten Kanten
for edge in edges:
gewicht, u, v = edge
# Wenn das Einschließen dieser Kante keinen Zyklus verursacht, schließe sie ein
if uf.union(u, v):
mst.append((u, v, gewicht))
total_cost += gewicht
# Optimierung: Früher Stopp, wenn wir V-1 Kanten haben
if len(mst) == vertices_count - 1:
break
return mst, total_cost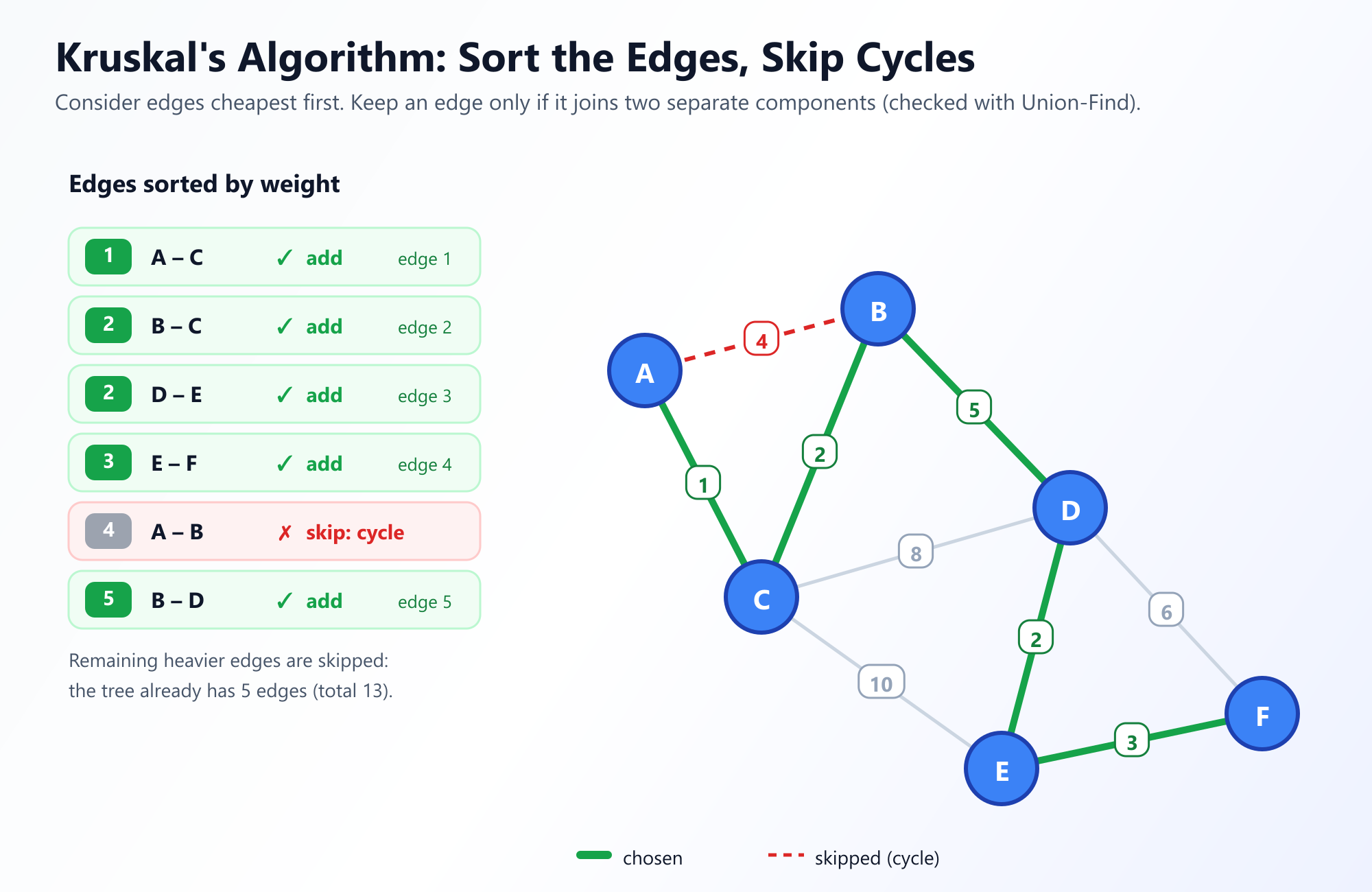
5. Prim vs. Kruskal: Welchen soll man wählen?
Obwohl beide Algorithmen garantiert das exakt selbe minimale Spannbaumgewicht finden, variiert ihre Leistung je nach Topologie des verarbeiteten Graphen erheblich.
| Metrik | Algorithmus von Prim | Algorithmus von Kruskal |
|---|---|---|
| Datenstruktur | Prioritätswarteschlange (Min-Heap) | Disjunkte Menge (Union-Find) |
| Zeitkomplexität | O(E log V) unter Verwendung eines binären Heaps. |
O(E log E) oder O(E log V), stark dominiert vom Sortieren der Kanten. |
| Graphendichte | Hervorragend für dichte Graphen. Da er nur benachbarte Kanten von besuchten Knoten betrachtet, ist er viel leistungsfähiger, wenn die Anzahl der Kanten E nahe bei V² liegt. |
Hervorragend für dünn besetzte Graphen. Da der erste Schritt darin besteht, alle Kanten zu sortieren, macht eine geringere Anzahl von Kanten die Sortierung rasend schnell. |
| Implementierungskomplexität | Kann aufgrund der Verwaltung der Prioritätswarteschlange und der Verfolgung der besuchten Zustände etwas komplexer sein. | Sehr unkompliziert zu implementieren, vorausgesetzt, Sie verfügen über eine vorgefertigte Union-Find-Klasse. |
| Wachstumsmuster | Lässt einen einzelnen, zusammenhängenden Baum wachsen. | Lässt einen Wald aus disjunkten Bäumen wachsen, die schließlich verschmelzen. |
6. Reale Anwendungen von MSTs
Der minimale Spannbaum ist nicht nur ein theoretisches Konstrukt; er wird aktiv in verschiedenen Ingenieursdisziplinen eingesetzt, um Kosten zu minimieren und das Routing zu optimieren.
- Netzwerkdesign: Telekommunikation, Stromnetze, Wasserversorgungsnetze und Computernetzwerke verwenden MST-Algorithmen, um sicherzustellen, dass alle Knoten mit der geringstmöglichen Menge an physischem Draht oder Rohr verbunden sind.
- Approximationsalgorithmen: MSTs werden häufig als Sprungbrett zur Lösung schwierigerer NP-schwerer Probleme verwendet, wie z. B. der Approximation des Problems des Handlungsreisenden (Traveling Salesperson Problem, TSP).
- Clusteranalyse: Im maschinellen Lernen und Data Mining stützt sich das Single-Linkage-Clustering auf Kruskals Algorithmus, um Datenpunkte basierend auf ihrer kürzesten Entfernung zu anderen Clustern zu gruppieren.
- Bildsegmentierung: MST-Algorithmen können verwendet werden, um ein Bild basierend auf der Pixelähnlichkeit in unterschiedliche Regionen oder Objekte zu unterteilen.
Häufig gestellte Fragen
Was ist ein Minimaler Spannbaum (MST)?
Ein Teilgraph eines zusammenhängenden, gewichteten ungerichteten Graphen, der alle Knoten kreisfrei und mit minimalem Gesamtgewicht verbindet.
Wie verhindert Union-Find Zyklen in Kruskals Algorithmus?
Union-Find verwaltet zusammenhängende Mengen. Bevor eine Kante u-v hinzugefügt wird, prüft Kruskal, ob u und v im selben Set sind. Wenn ja, wird die Kante verworfen.
Kann ein Graph mehrere minimale Spannbäume haben?
Ja, wenn Kanten gleiche Gewichte aufweisen. Wenn alle Kantengewichte eindeutig sind, gibt es genau einen eindeutigen MST.