
Tabla de Contenidos
El recorrido de grafos es el mecanismo fundamental de casi todos los algoritmos de la teoría de grafos. Es el proceso sistemático de visitar, verificar, analizar y a menudo actualizar cada vértice (nodo) en un grafo. Ya sea que estés buscando la ruta más corta en Google Maps, recomendando amigos en una red social, rastreando Internet para un motor de búsqueda o resolviendo un rompecabezas complejo algorítmicamente, estás utilizando el recorrido de grafos.
En el corazón de este dominio se encuentran dos algoritmos legendarios: la Búsqueda en Anchura (Breadth-First Search, BFS) y la Búsqueda en Profundidad (Depth-First Search, DFS). Si bien ambos garantizan que cada nodo accesible en un componente conectado será visitado exactamente una vez, el orden y la estrategia mediante los cuales visitan los nodos conducen a aplicaciones, complejidades de tiempo/espacio y patrones de comportamiento drásticamente diferentes.
En esta guía completa, analizaremos ambos algoritmos, examinaremos sus estructuras de datos, revisaremos el código de implementación, compararemos sus complejidades y finalmente veremos escenarios del mundo real para ayudarte a responder con confianza a la pregunta definitiva: "¿Cuándo debería usar BFS y cuándo DFS?"
1. Profundizando en la Búsqueda en Anchura (BFS)
La Búsqueda en Anchura explora el grafo en "ondas" concéntricas. Comienza en un nodo raíz elegido (o en cualquier nodo de inicio) y visita primero a todos sus vecinos inmediatos. Solo después de agotar completamente todos los nodos a una distancia de exactamente 1 arista, pasa a los nodos a la distancia 2, y así sucesivamente.
La analogía de la gota de agua: Piensa en BFS como una gota de agua que crea ondas en un estanque en reposo. La onda se expande hacia afuera uniformemente en todas las direcciones. No sale disparada en línea recta; cubre el área de manera uniforme por radio.
La Mecánica de BFS
Para asegurar que los nodos sean visitados estrictamente por niveles, BFS confía en una estructura de datos de tipo Cola (Queue) (First-In, First-Out, o FIFO) para hacer un seguimiento de qué nodos deben visitarse a continuación.
El algoritmo BFS estándar sigue estos pasos:
- Inicializa una Cola y un array booleano (o Hash Set) para hacer un seguimiento de los nodos
visitados. - Encola el nodo de inicio y márcalo inmediatamente como
visitado. - Inicia un bucle que continúa mientras la Cola no esté vacía.
- Saca de la cola el nodo frontal. Este es tu nodo actual. Procésalo como desees.
- Itera sobre cada vecino adyacente de este nodo actual.
- Si un vecino no ha sido visitado, márcalo como
visitadoy encolalo. - Repite hasta que la Cola esté vacía.
Ejemplo de Implementación BFS
A continuación se muestra una implementación limpia de BFS en Python utilizando una representación de lista de adyacencia y la altamente eficiente collections.deque.
from collections import deque
def breadth_first_search(graph, start_node):
# Inicializa una cola y un set para los nodos visitados
queue = deque([start_node])
visited = {start_node}
# Almacena el orden de recorrido
traversal_order = []
while queue:
# Saca el nodo del frente de la cola
current_node = queue.popleft()
traversal_order.append(current_node)
# Obtén todos los nodos adyacentes del nodo sacado de la cola
for neighbor in graph[current_node]:
if neighbor not in visited:
# Marca como visitado inmediatamente ANTES de encolar
# para evitar entradas duplicadas en la cola
visited.add(neighbor)
queue.append(neighbor)
return traversal_order
# Grafo de ejemplo (Lista de adyacencia)
graph = {
'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']
}
print(breadth_first_search(graph, 'A'))
# Salida: ['A', 'B', 'C', 'D', 'E', 'F']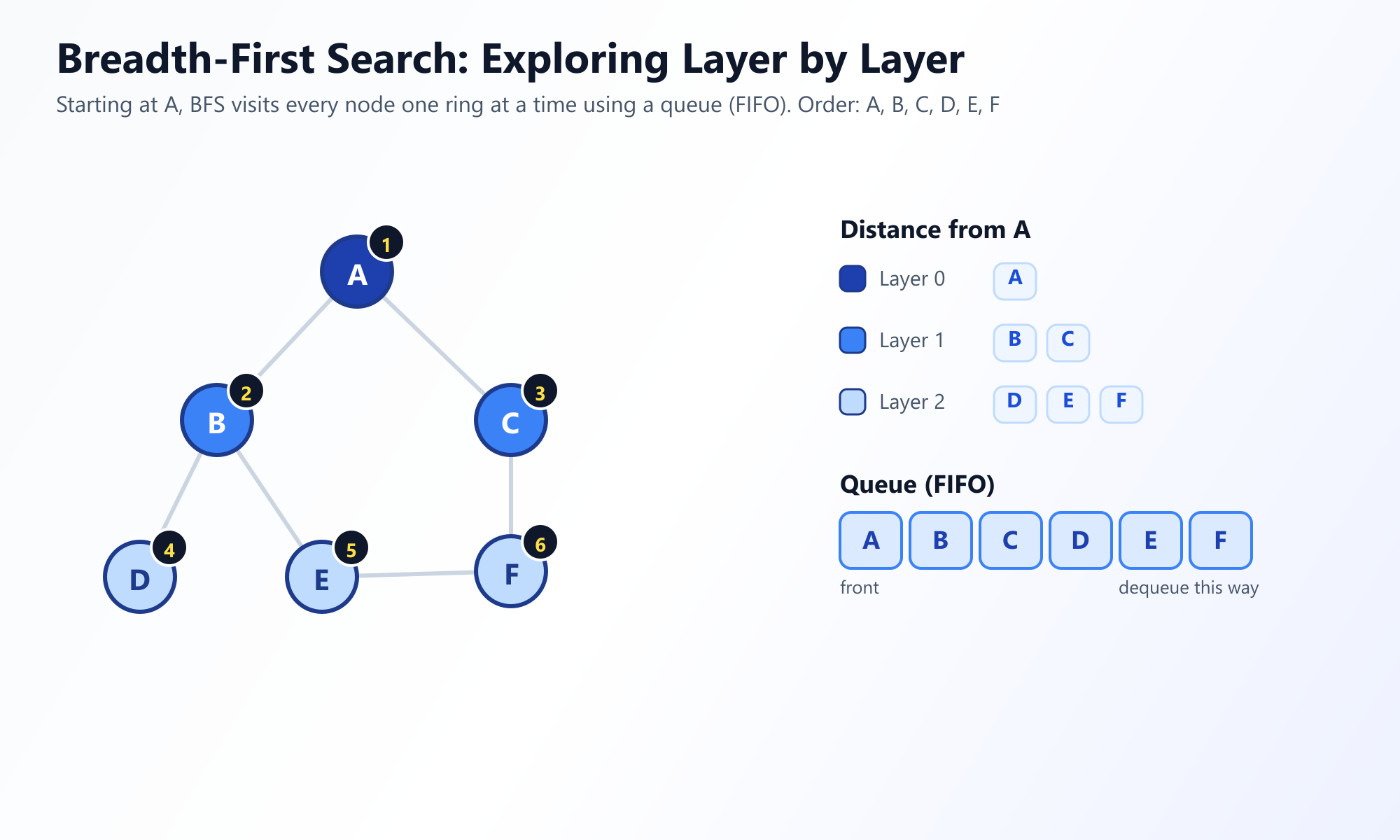
Deja de leer, comienza a visualizar
Leer código es bueno, pero observar cómo se ejecuta el algoritmo en tiempo real crea verdadera intuición. Mira cómo la Cola administra la onda BFS en nuestra plataforma.
Lanzar Visualizador BFS Interactivo2. Profundizando en la Búsqueda en Profundidad (DFS)
La Búsqueda en Profundidad toma un enfoque drásticamente diferente y más agresivo. En lugar de explorar a lo ancho, explora profundamente. Comienza en un nodo raíz y explora lo más lejos posible a lo largo de una rama singular hasta que llega a un "callejón sin salida" (un nodo sin vecinos no visitados). Una vez atascado, retrocede (backtracking) por el camino lo suficiente para encontrar una nueva rama inexplorada por la cual sumergirse.
La analogía del laberinto: Piensa en DFS como navegar por un laberinto físico. Pones tu mano en la pared derecha y sigues caminando hacia adelante. Tomas giro tras giro hasta que llegas a un callejón sin salida. En ese momento, te das la vuelta, caminas de regreso a la última intersección y tomas el camino inexplorado.
La Mecánica de DFS
Debido a que DFS necesita recordar de dónde vino para poder retroceder, utiliza una estructura de datos de tipo Pila (Stack) (Last-In, First-Out, o LIFO). Comúnmente, los desarrolladores implementan DFS de forma recursiva, utilizando elegantemente la pila de llamadas nativa de la CPU en lugar de crear un objeto Pila manual.
El algoritmo DFS recursivo estándar sigue estos pasos:
- Comienza en el nodo actual y márcalo inmediatamente como
visitado. - Procesa el nodo (por ejemplo, imprime su valor).
- Itera sobre todos sus vecinos adyacentes.
- Si un vecino no ha sido visitado, llama recursivamente a la función DFS en ese vecino.
- Cuando el bucle termina (no quedan vecinos no visitados), la función retorna, retrocediendo automáticamente al llamador anterior en la pila.
Ejemplo de Implementación DFS
A continuación se muestra una elegante implementación recursiva de DFS en Python.
def depth_first_search_recursive(graph, current_node, visited=None, traversal_order=None):
# Inicializa colecciones en la llamada inicial
if visited is None:
visited = set()
if traversal_order is None:
traversal_order = []
# Marca el nodo actual como visitado y regístralo
visited.add(current_node)
traversal_order.append(current_node)
# Visita recursivamente todos los vecinos no visitados
for neighbor in graph[current_node]:
if neighbor not in visited:
depth_first_search_recursive(graph, neighbor, visited, traversal_order)
return traversal_order
# Grafo de ejemplo (Lista de adyacencia)
graph = {
'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'], 'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']
}
print(depth_first_search_recursive(graph, 'A'))
# Salida: ['A', 'B', 'D', 'E', 'F', 'C']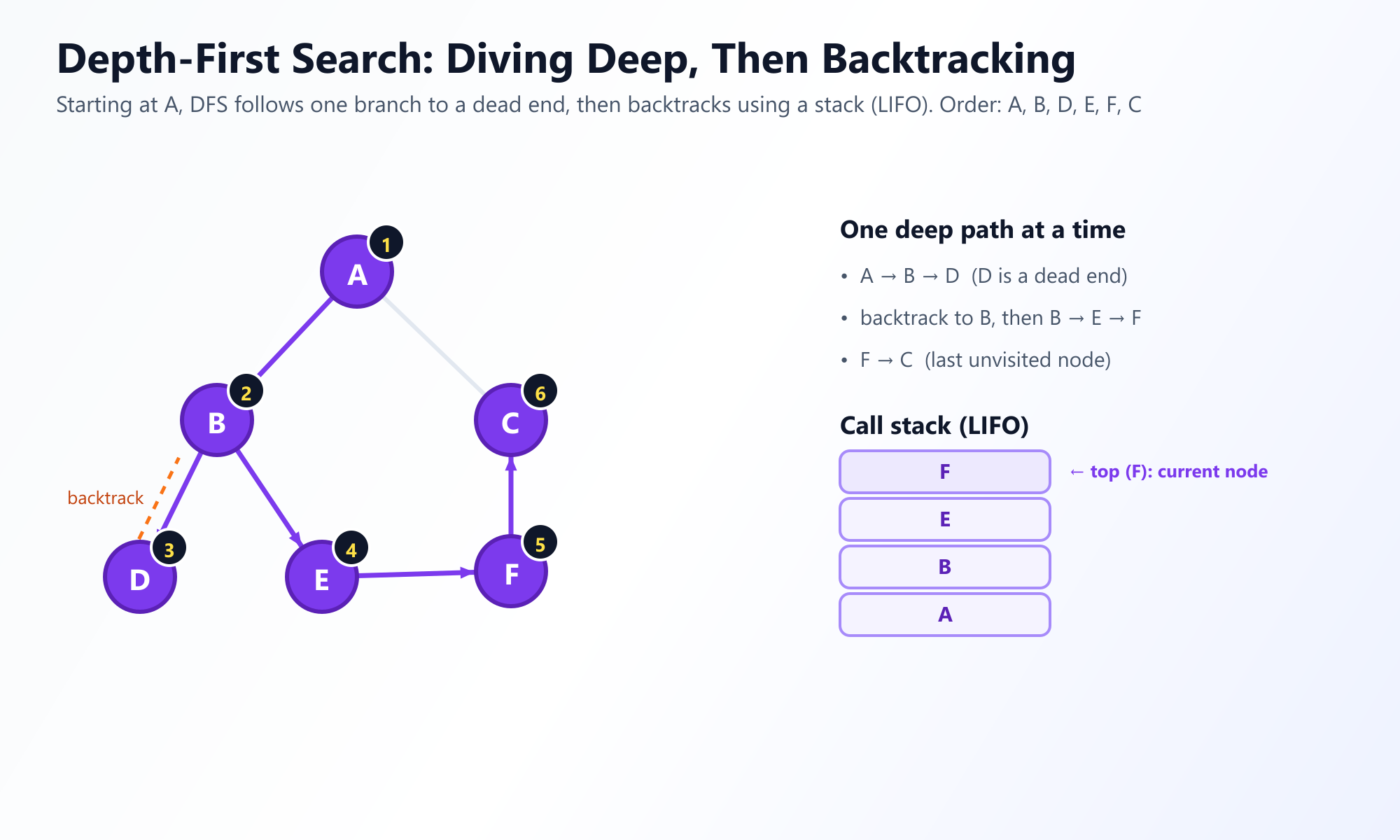
Nota la diferencia en la salida en comparación con BFS. DFS persiguió agresivamente el camino A a B a D antes de retroceder.
Visualiza la magia del Backtracking
Las pilas de llamadas recursivas pueden ser difíciles de mapear mentalmente. Observa cómo DFS profundiza y retrocede visualmente por los bordes cuando se atasca.
Lanzar Visualizador DFS Interactivo3. BFS vs. DFS: La comparación definitiva
En entrevistas técnicas y en el diseño de sistemas del mundo real, elegir el algoritmo de recorrido equivocado puede resultar en un agotamiento catastrófico de la memoria o en tiempos de ejecución altamente ineficientes. Analicemos las diferencias técnicas.
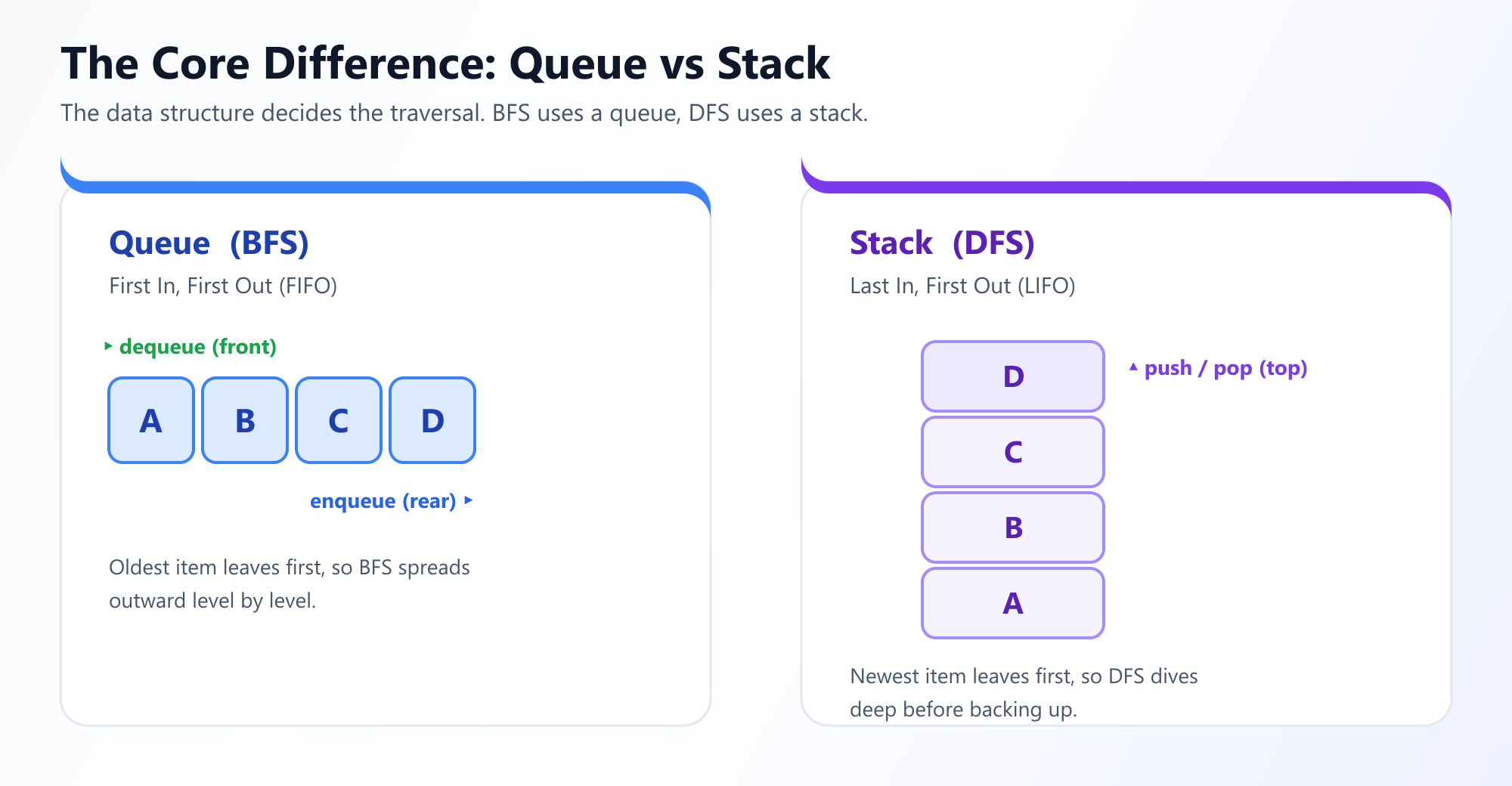
| Métrica | Búsqueda en Anchura (BFS) | Búsqueda en Profundidad (DFS) |
|---|---|---|
| Estructura de Datos | Cola (FIFO) - Enfoque Iterativo | Pila (LIFO) - Frecuentemente enfoque Recursivo |
| Complejidad de Tiempo | O(V + E)Debe visitar cada Vértice y comprobar cada Arista. |
O(V + E)Igualmente visita cada Vértice y explora cada Arista. |
| Complejidad de Espacio | O(W) donde W es la anchura máxima del grafo.Puede ser O(V) en grafos densos en el peor de los casos. |
O(H) donde H es la profundidad/altura máxima del grafo.Puede ser O(V) si el grafo es una sola línea larga. |
| Garantía de ruta más corta | Sí. Para grafos no ponderados, BFS garantiza encontrar la ruta más corta. | No. DFS podría encontrar una ruta masiva y enrevesada antes de la ruta corta y directa. |
| Sobrecarga de memoria | Alta si el árbol/grafo es muy ancho (ej. red social). La cola debe contener todos los nodos del nivel actual. | Alta si el árbol/grafo es muy profundo. La pila de llamadas debe contener todos los ancestros del nodo actual. |
| Optimalidad | Óptimo para encontrar objetivos cercanos a la fuente. | Óptimo para encontrar objetivos lejos de la fuente o explorar todas las posibilidades. |
Comprendiendo el compromiso de la Complejidad de Espacio
Si bien ambos algoritmos comparten una complejidad de tiempo de O(V + E), sus complejidades de espacio difieren drásticamente dependiendo de la topología del grafo.
- Grafos Anchos: Si un grafo tiene un factor de ramificación masivo (como un árbol DOM de HTML o un grafo de seguidores de Twitter), la cola BFS aumentará de tamaño ya que debe almacenar todo un "nivel" del grafo a la vez. En estos escenarios, DFS es altamente eficiente en memoria.
- Grafos Profundos: Si un grafo es extremadamente profundo (como una cadena de bloques masiva o un árbol de decisiones profundo), DFS podría exceder la profundidad máxima de recursividad o consumir demasiada memoria de pila. En estos escenarios, BFS podría ser preferible, aunque la profundización iterativa DFS es a menudo la solución utilizada en producción.
4. Aplicaciones en el mundo real: ¿Cuándo usar cuál?
La elección entre BFS y DFS generalmente se reduce a lo que intentas extraer de la estructura del grafo.
Usar Búsqueda en Anchura (BFS) cuando:
- Encontrar la ruta más corta (Grafos no ponderados): Debido a que BFS explora nivel por nivel, la primera vez que se encuentra con el nodo objetivo, definitivamente ha tomado el número mínimo de aristas para llegar allí. Los algoritmos de enrutamiento GPS a menudo utilizan variaciones de BFS (como Dijkstra) por esta misma razón.
- Es probable que el objetivo esté cerca de la fuente: Si estás buscando un primo inmediato en un árbol genealógico, BFS lo encontrará de inmediato. DFS podría explorar una rama completamente diferente de la familia hasta el siglo XVI antes de verificar al primo.
- Redes Peer-to-Peer: Protocolos como BitTorrent utilizan BFS para encontrar nodos vecinos. "Encuentra todos los pares a 1 salto de distancia, luego a 2 saltos de distancia".
- Rastreadores Web: Los motores de búsqueda como Google utilizaban originalmente BFS para rastrear la web. Quieres indexar los enlaces más destacados de la página principal antes de sumergirte profundamente en subpáginas anidadas y oscuras.
- "Grados de Separación" en Redes Sociales: Funciones como la "conexión de 2º grado" de LinkedIn se basan completamente en los límites de BFS.
Usar Búsqueda en Profundidad (DFS) cuando:
- Comprobar la existencia de ciclos: DFS está equipado de manera única para encontrar aristas de retroceso (aristas que apuntan a un ancestro). Si existe una arista de retroceso, el grafo tiene un ciclo. Esto es fundamental para evitar bucles infinitos en enrutadores y detectar bloqueos mutuos (deadlocks) en sistemas operativos.
- Ordenación Topológica: En sistemas de construcción (como Make, Webpack o npm), las tareas tienen dependencias. DFS se utiliza para ordenar linealmente estas tareas de modo que cada tarea se ejecute solo después de que se satisfagan sus dependencias.
- La memoria es una restricción severa (y el grafo es ancho): Como se mencionó, DFS solo necesita almacenar el camino desde la raíz hasta el nodo actual, lo que lo hace increíblemente eficiente en memoria para grafos anchos y masivos como árboles de estado de juegos (ej. motores de ajedrez).
- Resolver Rompecabezas y Laberintos: DFS es el algoritmo de referencia para resolver Sudokus, el problema de las N-Reinas o construir/resolver laberintos físicos. Explora agresivamente una posible solución y, si falla, simplemente retrocede y prueba la siguiente configuración.
- Encontrar Componentes Fuertemente Conexos: Algoritmos como Tarjan o Kosaraju se basan en gran medida en DFS para agrupar nodos en clústeres fuertemente conectados.
5. Variaciones Avanzadas
En la informática moderna, tanto BFS como DFS básicos a menudo se aumentan para manejar escalas masivas.
- BFS Bidireccional: En lugar de ejecutar BFS desde la fuente hasta el destino, ejecuta dos ondas BFS simultáneas: una desde la fuente y otra desde el destino. Cuando las ondas se cruzan, has encontrado la ruta más corta. Esto reduce drásticamente el espacio de búsqueda.
- Profundización Iterativa DFS (IDDFS): Esto combina la eficiencia de memoria de DFS con la garantía de ruta más corta de BFS. Ejecuta un DFS pero establece un límite de profundidad estricto. Si no se encuentra el objetivo, aumenta el límite de profundidad y comienza de nuevo. Se utiliza mucho en Inteligencia Artificial y análisis de árboles de juegos.
Conclusión
La Búsqueda en Anchura y la Búsqueda en Profundidad son las piedras angulares indiscutibles de la teoría de grafos. BFS es tu onda expansiva nivel por nivel, perfecta para rutas más cortas y análisis de redes amplias. DFS es tu corredor de laberintos agresivo y eficiente en memoria, perfecto para la detección de ciclos, la clasificación topológica y la resolución de rompecabezas profundos.
Dominar ambos algoritmos es no negociable para aprobar entrevistas técnicas en las principales empresas tecnológicas y diseñar arquitecturas de software robustas y escalables.
Preguntas frecuentes
¿Cuándo debo elegir BFS en lugar de DFS?
Elige BFS (búsqueda en anchura) cuando necesites encontrar el camino más corto en un grafo no ponderado o el nodo objetivo esté cerca del punto de inicio.
¿Cuándo es DFS más ventajoso que BFS?
DFS (búsqueda en profundidad) es mejor para explorar todas las opciones (como laberintos), realizar ordenamiento topológico, detectar ciclos o cuando la memoria es limitada.
¿Cómo difieren las estructuras de datos de BFS y DFS?
BFS utiliza una Cola (FIFO) para explorar nivel por nivel. DFS utiliza una Pila (LIFO), a menudo implementada de forma implícita a través de la recursión.