
Table of Contents
1. What is a Minimum Spanning Tree (MST)?
Imagine you are tasked with designing a new telecommunications network for a city. You have a map with several neighborhoods (nodes) and the possible routes where you can lay fiber-optic cables (edges). Laying cable is expensive, and the cost varies depending on the terrain (edge weights).
Your goal is to ensure that every neighborhood is connected to the network, meaning there is a path from any neighborhood to any other neighborhood. However, to save money, you want the total cost of laying the cables to be as small as possible. You don't need redundant connections; as long as everything is connected, you are satisfied.
This exact scenario is the textbook definition of the Minimum Spanning Tree (MST) problem.
Let's break down the terminology:
- Tree: A connected graph with absolutely no cycles. If you have
Vvertices, a tree will always have exactlyV - 1edges. - Spanning: It covers (spans) every single vertex in the original graph.
- Minimum: Among all the possible spanning trees that could be drawn over the graph, this one has the smallest total edge weight.
It is important to note that a graph might have multiple Minimum Spanning Trees if several edges share the same weights, but the minimum total weight will always be unique.
To solve this problem, computer science relies heavily on two legendary Greedy Algorithms: Prim's Algorithm and Kruskal's Algorithm.
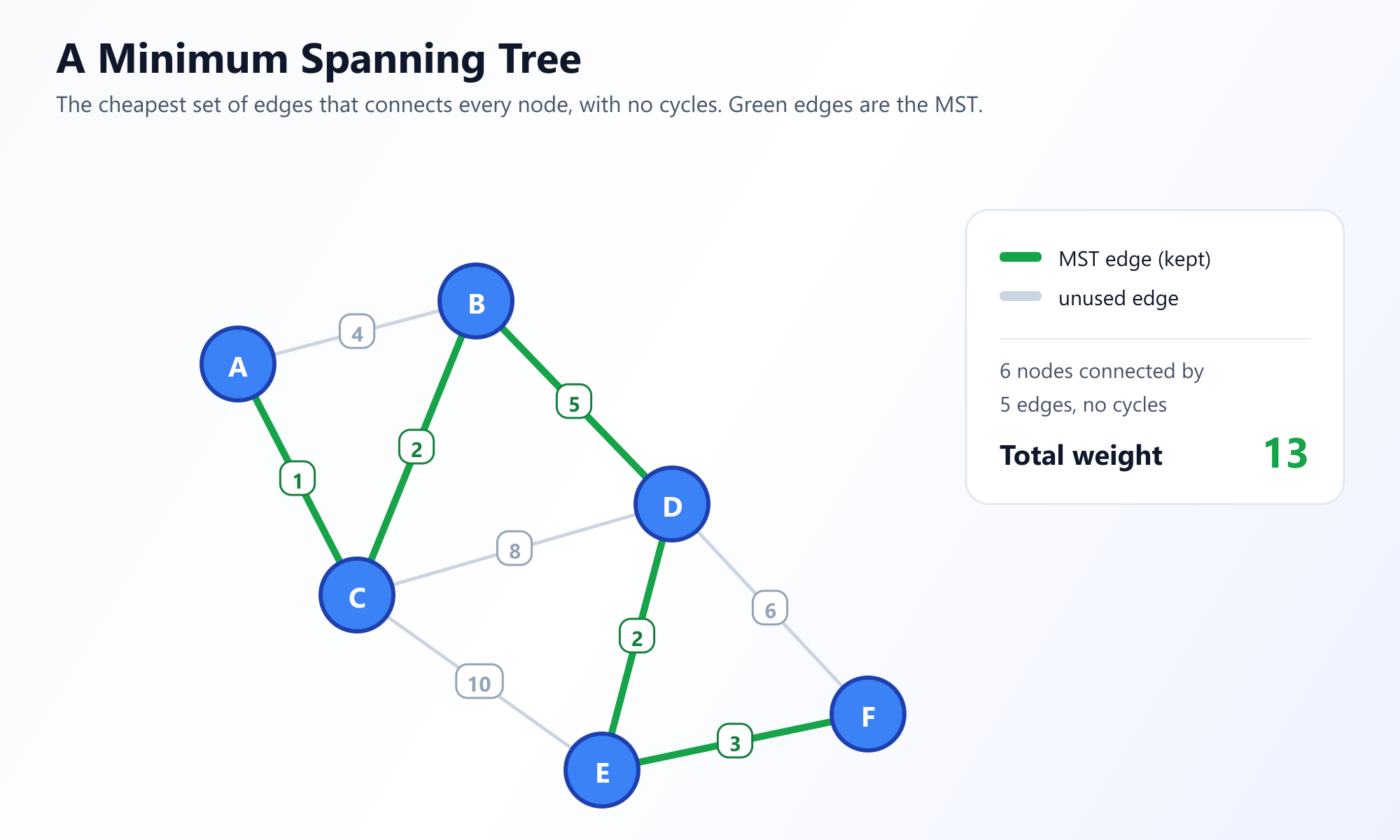
2. Prim's Algorithm: The Node-Centric Approach
Prim's Algorithm was originally designed in 1930 by mathematician Vojtěch Jarník, and later rediscovered and popularized by Robert Prim in 1957. Prim's takes a node-centric approach, slowly growing the tree outward from a single starting vertex, much like a mold spreading on a piece of bread.
The Strategy: Start at any arbitrary node. Look at all the edges connecting the nodes in your current growing tree to nodes outside the tree. Pick the edge with the lowest weight. Add that edge and the new node to your tree. Repeat until all nodes are included.
The Mechanics
To efficiently find the lowest weight edge connecting the tree to the outside world, Prim's algorithm heavily utilizes a Priority Queue (Min-Heap), making it very similar in structure to Dijkstra's Shortest Path Algorithm.
- Initialize a boolean array to keep track of nodes already included in the MST.
- Initialize a Priority Queue to store tuples of
(edge_weight, destination_node). - Pick a random starting node, mark it as included, and push all its edges into the Priority Queue.
- While the Priority Queue is not empty and the MST doesn't have
V - 1edges: - Pop the edge with the minimum weight.
- If the destination node is already in the MST, ignore it (to prevent cycles).
- Otherwise, add the edge to the MST, mark the new node as included, and push all edges radiating from this new node into the Priority Queue.
Prim's Algorithm in Python
import heapq
def prims_algorithm(graph, start_node):
# graph is represented as an adjacency list:
# graph[u] = [(weight, v), ...]
mst = []
visited = set([start_node])
# Initialize the priority queue with edges from the start node
edges = [ (weight, start_node, to_node) for weight, to_node in graph[start_node] ]
heapq.heapify(edges)
total_cost = 0
while edges:
weight, frm, to = heapq.heappop(edges)
# If the destination is not visited, it's a safe edge
if to not in visited:
visited.add(to)
mst.append((frm, to, weight))
total_cost += weight
# Push all edges originating from the newly visited node
for next_weight, next_to in graph[to]:
if next_to not in visited:
heapq.heappush(edges, (next_weight, to, next_to))
return mst, total_cost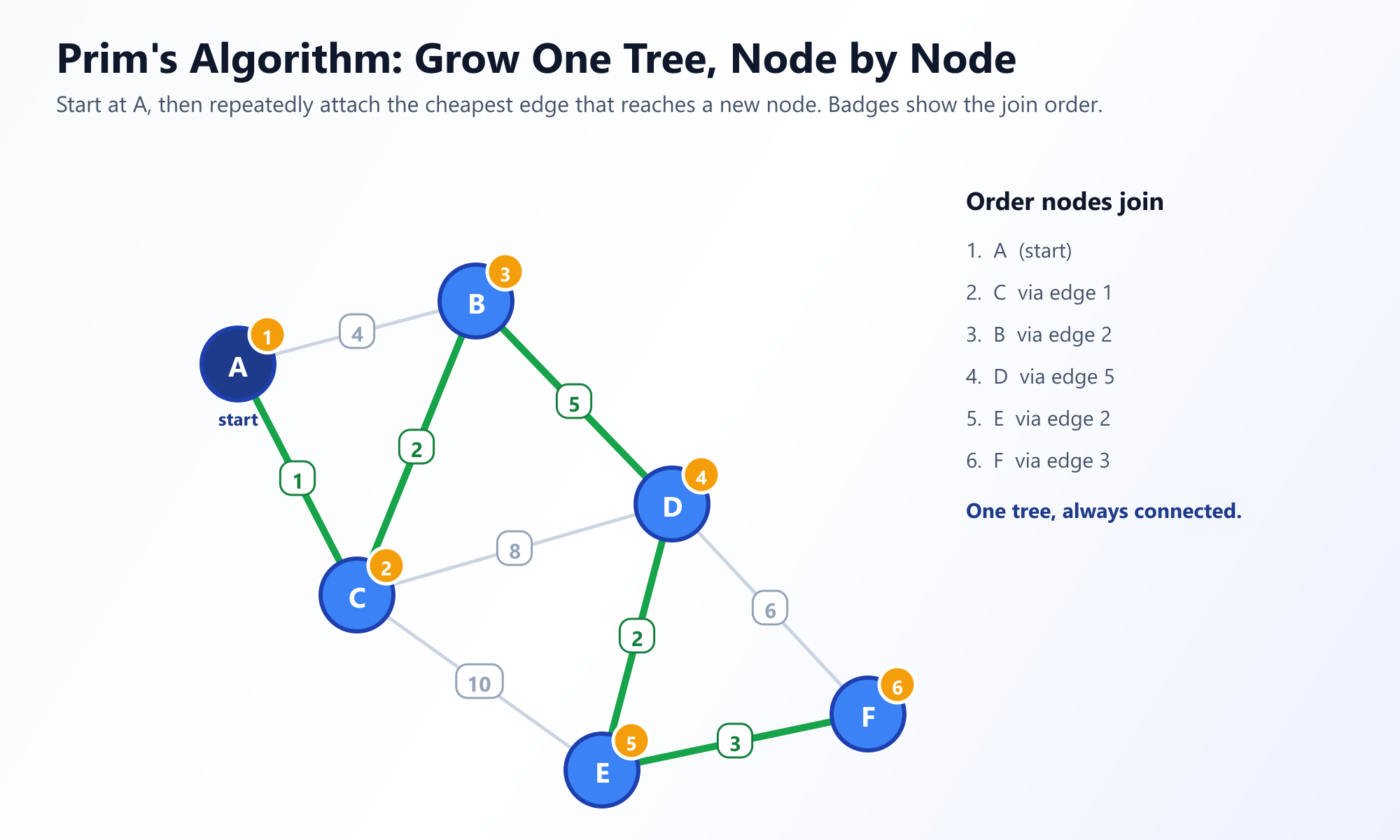
Visualize Prim's Algorithm Growing
Watch how the Priority Queue evaluates the "frontier" edges in real-time. Seeing the tree grow node by node is the best way to internalize the greedy choice.
Launch Interactive Prim's Visualizer3. Kruskal's Algorithm: The Edge-Centric Approach
Joseph Kruskal published his algorithm in 1956. Unlike Prim, which grows a single continuous tree from a root, Kruskal takes an edge-centric approach. It looks at the graph as a whole, focusing entirely on the edges rather than the nodes.
The Strategy: Throw all the edges in a pile and sort them from smallest weight to largest weight. Pick up the smallest edge. If adding this edge to your MST does not create a cycle, keep it. If it creates a cycle, throw it away. Repeat until you have V - 1 edges.
Initially, Kruskal's algorithm treats every node as its own separate tree. As it adds edges, it merges these small trees into larger forests, until eventually, there is only one massive tree spanning the entire graph.
4. The Secret Sauce: Union-Find Disjoint Sets
The entire logic of Kruskal's algorithm hinges on one crucial step: "If adding this edge does not create a cycle."
How can we efficiently determine if connecting Node A and Node B will create a cycle? Running a full DFS every time we want to add an edge would be painfully slow. This is where the brilliant Union-Find Disjoint Set data structure comes to the rescue.
A Union-Find data structure keeps track of elements partitioned into a number of disjoint (non-overlapping) subsets. It supports two primary operations in near constant O(1) time:
- Find: Determine which set a particular element belongs to. (Usually by finding the "root" or "representative" of the set).
- Union: Join two subsets into a single subset.
When evaluating an edge between Node A and Node B, we simply call Find(A) and Find(B). If they return the same root, they are already in the same connected component, meaning adding an edge between them would create a cycle. If they return different roots, it is safe to add the edge, and we call Union(A, B).
Kruskal's Algorithm in Python
class UnionFind:
def __init__(self, size):
# Initially, every node is its own parent (root)
self.parent = [i for i in range(size)]
self.rank = [0] * size
def find(self, i):
# Path compression optimization
if self.parent[i] == i:
return i
self.parent[i] = self.find(self.parent[i])
return self.parent[i]
def union(self, i, j):
root_i = self.find(i)
root_j = self.find(j)
if root_i != root_j:
# Union by rank optimization
if self.rank[root_i] < self.rank[root_j]:
self.parent[root_i] = root_j
elif self.rank[root_i] > self.rank[root_j]:
self.parent[root_j] = root_i
else:
self.parent[root_j] = root_i
self.rank[root_i] += 1
return True
return False
def kruskals_algorithm(vertices_count, edges):
# edges is a list of tuples: [(weight, u, v), ...]
# Step 1: Sort all edges in non-decreasing order of their weight
edges.sort()
uf = UnionFind(vertices_count)
mst = []
total_cost = 0
# Step 2: Iterate through the sorted edges
for edge in edges:
weight, u, v = edge
# If including this edge does not cause a cycle, include it
if uf.union(u, v):
mst.append((u, v, weight))
total_cost += weight
# Optimization: Stop early if we have V-1 edges
if len(mst) == vertices_count - 1:
break
return mst, total_cost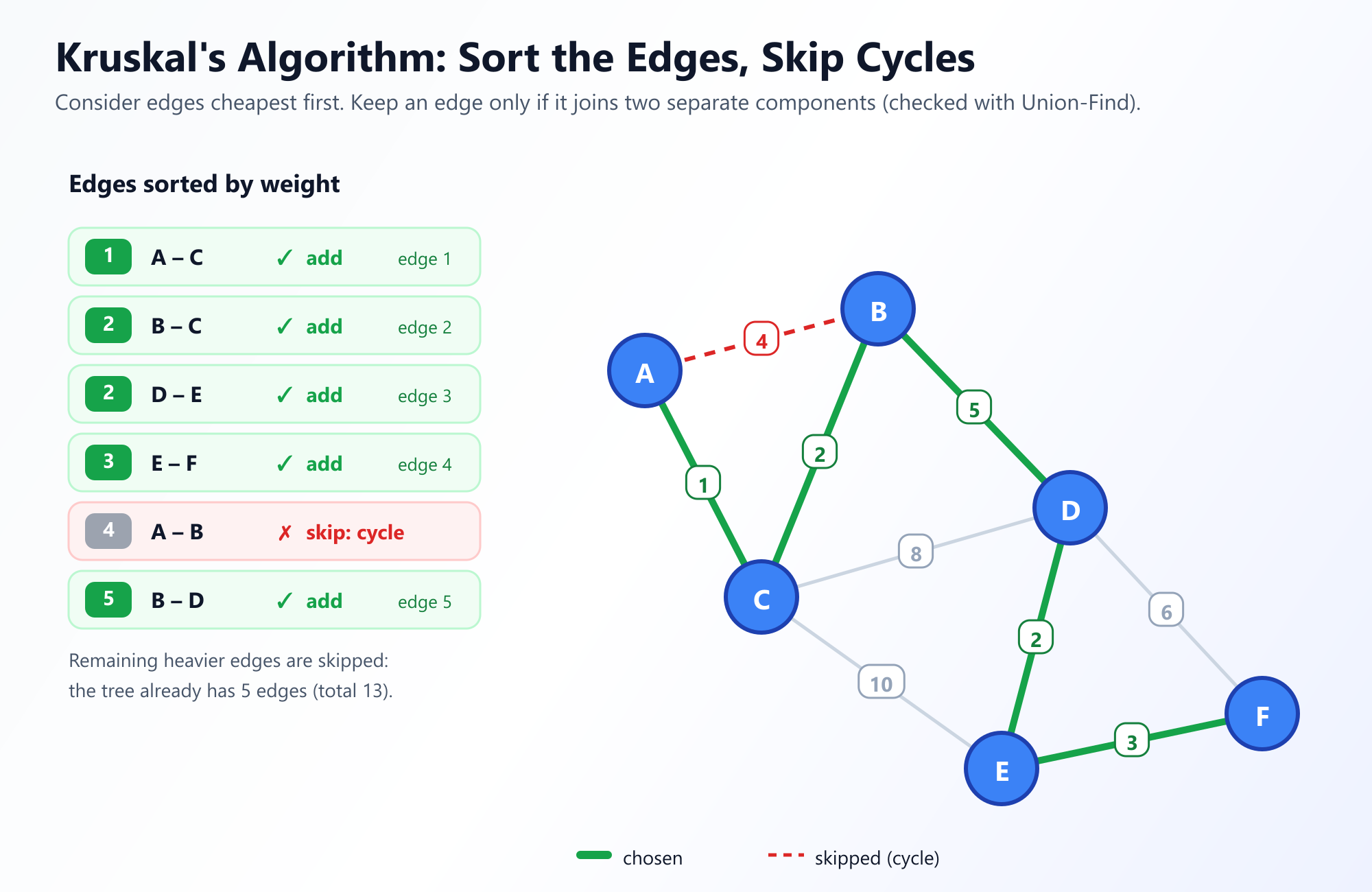
5. Prim vs. Kruskal: Which one to choose?
While both algorithms are guaranteed to find the exact same minimum spanning tree weight, their performance varies significantly based on the topology of the graph being processed.
| Metric | Prim's Algorithm | Kruskal's Algorithm |
|---|---|---|
| Data Structure | Priority Queue (Min-Heap) | Disjoint Set (Union-Find) |
| Time Complexity | O(E log V) using a Binary Heap. |
O(E log E) or O(E log V) heavily dominated by sorting the edges. |
| Graph Density | Excellent for Dense Graphs. Since it only looks at adjacent edges of visited nodes, it performs much better when the number of edges E is close to V². |
Excellent for Sparse Graphs. Since the first step is sorting all edges, having fewer edges makes the sort blazingly fast. |
| Implementation Complexity | Can be slightly more complex due to managing the Priority Queue and tracking visited states. | Very straightforward to implement, provided you have a pre-written Union-Find class. |
| Growth Pattern | Grows a single, contiguous tree. | Grows a forest of disjoint trees that eventually merge together. |
6. Real World Applications of MSTs
The Minimum Spanning Tree is not just a theoretical construct; it is actively used in various engineering disciplines to minimize costs and optimize routing.
- Network Design: Telecommunications, electrical grids, water supply networks, and computer networks use MST algorithms to ensure all nodes are connected with the minimum amount of physical wire or pipe.
- Approximation Algorithms: MSTs are frequently used as a stepping stone to solve harder NP-Hard problems, such as the Traveling Salesperson Problem (TSP) approximation.
- Cluster Analysis: In machine learning and data mining, Single-Linkage Clustering relies on Kruskal's algorithm to group data points based on their shortest distance to other clusters.
- Image Segmentation: MST algorithms can be used to partition an image into distinct regions or objects based on pixel similarity.
Frequently Asked Questions
What is a Minimum Spanning Tree (MST)?
An MST is a subset of the edges of a connected, edge-weighted undirected graph that connects all the vertices together, without any cycles and with the minimum possible total edge weight.
How does Union-Find prevent cycles in Kruskal's algorithm?
Union-Find tracks connected components. Before adding an edge between u and v, Kruskal's checks if they belong to the same set. If they do, adding the edge would create a cycle, so it is skipped.
Can a graph have more than one MST?
Yes, a graph can have multiple MSTs if there are multiple edges with the same weight. If all edge weights in the graph are unique, there is only one unique MST.