
Table des Matières
- 1. Qu'est-ce qu'un Arbre Couvrant de Poids Minimum ?
- 2. Algorithme de Prim : L'Approche Centrée sur les Nœuds
- 3. Algorithme de Kruskal : L'Approche Centrée sur les Arêtes
- 4. L'Ingrédient Secret : Ensembles Disjoints (Union-Find)
- 5. Prim vs. Kruskal : Lequel Choisir ?
- 6. Applications dans le Monde Réel
- Foire Aux Questions (FAQ)
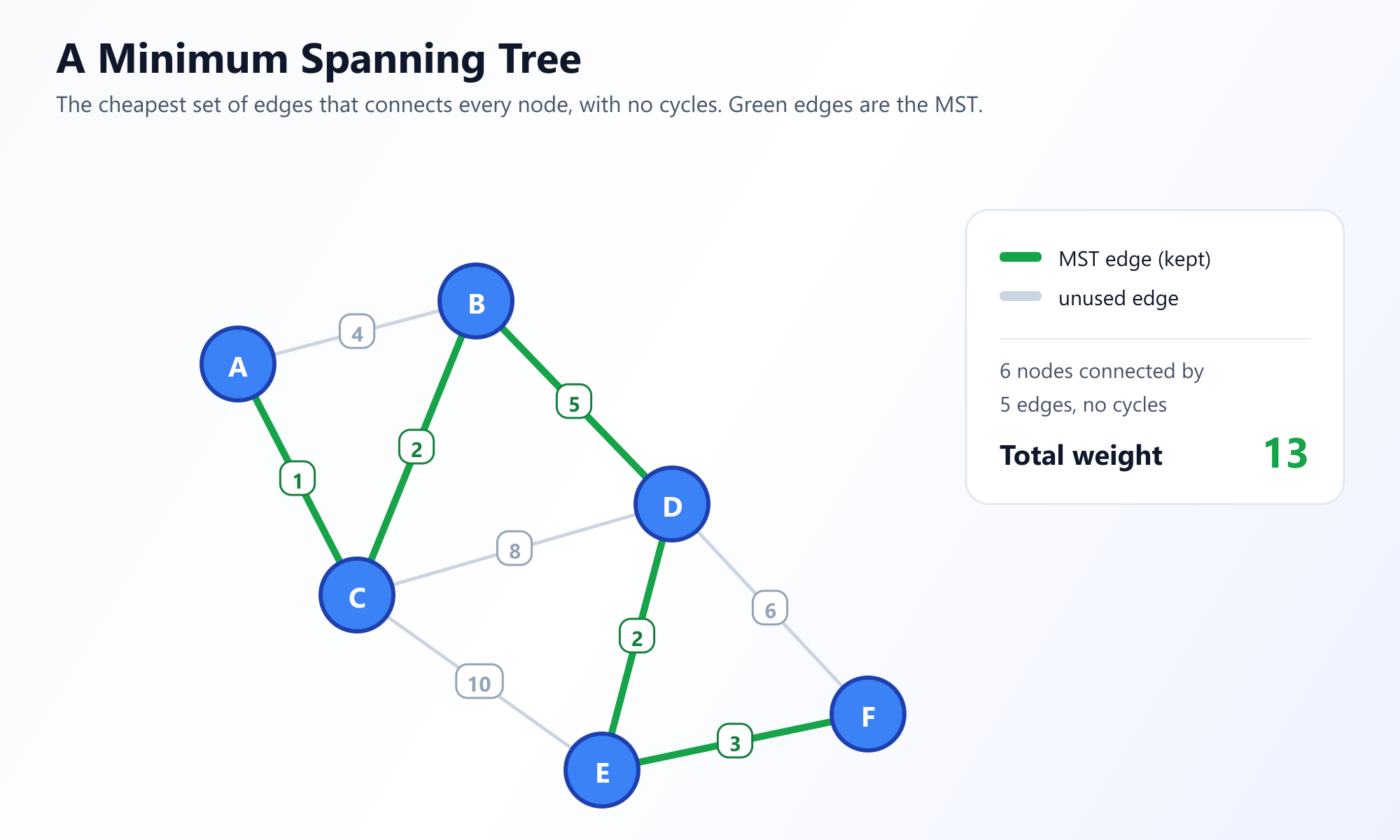
1. Qu'est-ce qu'un Arbre Couvrant de Poids Minimum (MST) ?
Imaginez que vous êtes chargé de concevoir un nouveau réseau de télécommunications pour une ville. Vous avez une carte avec plusieurs quartiers (nœuds) et les itinéraires possibles où vous pouvez poser des câbles à fibres optiques (arêtes). La pose de câbles coûte cher, et le coût varie selon le terrain (poids des arêtes).
Votre objectif est de vous assurer que chaque quartier est connecté au réseau, ce qui signifie qu'il y a un chemin depuis n'importe quel quartier vers n'importe quel autre quartier. Cependant, pour économiser de l'argent, vous voulez que le coût total de la pose des câbles soit aussi faible que possible. Vous n'avez pas besoin de connexions redondantes ; tant que tout est connecté, vous êtes satisfait.
Ce scénario exact est la définition classique du problème de l'Arbre Couvrant de Poids Minimum (Minimum Spanning Tree, MST).
Décomposons la terminologie :
- Arbre : Un graphe connexe sans aucun cycle. Si vous avez
Vsommets, un arbre aura toujours exactementV - 1arêtes. - Couvrant : Il couvre (relie) chaque sommet du graphe d'origine.
- Minimum : Parmi tous les arbres couvrants possibles qui pourraient être dessinés sur le graphe, celui-ci a le plus petit poids total des arêtes.
Il est important de noter qu'un graphe peut avoir plusieurs arbres couvrants de poids minimum si plusieurs arêtes partagent les mêmes poids, mais le poids total minimum sera toujours unique.
Pour résoudre ce problème, l'informatique s'appuie fortement sur deux algorithmes gloutons légendaires : l'Algorithme de Prim et l'Algorithme de Kruskal.
2. Algorithme de Prim : L'Approche Centrée sur les Nœuds
L'algorithme de Prim a été initialement conçu en 1930 par le mathématicien Vojtěch Jarník, puis redécouvert et popularisé par Robert Prim en 1957. Prim adopte une approche centrée sur les nœuds, faisant croître lentement l'arbre vers l'extérieur à partir d'un seul sommet de départ, un peu comme la moisissure se propage sur un morceau de pain.
La Stratégie : Commencez par un nœud arbitraire. Regardez toutes les arêtes reliant les nœuds de votre arbre en cours de croissance à des nœuds extérieurs à l'arbre. Choisissez l'arête ayant le poids le plus faible. Ajoutez cette arête et le nouveau nœud à votre arbre. Répétez jusqu'à ce que tous les nœuds soient inclus.
La Mécanique
Afin de trouver efficacement l'arête de poids le plus faible reliant l'arbre au monde extérieur, l'algorithme de Prim utilise fortement une File de Priorité (Min-Heap), ce qui le rend très similaire en structure à l'algorithme du plus court chemin de Dijkstra.
- Initialisez un tableau booléen pour garder une trace des nœuds déjà inclus dans le MST.
- Initialisez une file de priorité pour stocker des tuples de
(poids_arete, noeud_destination). - Choisissez un nœud de départ aléatoire, marquez-le comme inclus et insérez toutes ses arêtes dans la file de priorité.
- Tant que la file de priorité n'est pas vide et que le MST n'a pas
V - 1arêtes : - Extrayez l'arête avec le poids minimum.
- Si le nœud de destination est déjà dans le MST, ignorez-le (pour éviter les cycles).
- Sinon, ajoutez l'arête au MST, marquez le nouveau nœud comme inclus et insérez toutes les arêtes rayonnant de ce nouveau nœud dans la file de priorité.
Algorithme de Prim en Python
import heapq
def prims_algorithm(graph, start_node):
# graph est représenté comme une liste d'adjacence :
# graph[u] = [(poids, v), ...]
mst = []
visited = set([start_node])
# Initialise la file de priorité avec les arêtes du nœud de départ
edges = [ (poids, start_node, noeud_destination) for poids, noeud_destination in graph[start_node] ]
heapq.heapify(edges)
total_cost = 0
while edges:
poids, frm, to = heapq.heappop(edges)
# Si la destination n'est pas visitée, c'est une arête sûre
if to not in visited:
visited.add(to)
mst.append((frm, to, poids))
total_cost += poids
# Insérer toutes les arêtes provenant du nœud nouvellement visité
for prochain_poids, prochain_to in graph[to]:
if prochain_to not in visited:
heapq.heappush(edges, (prochain_poids, to, prochain_to))
return mst, total_cost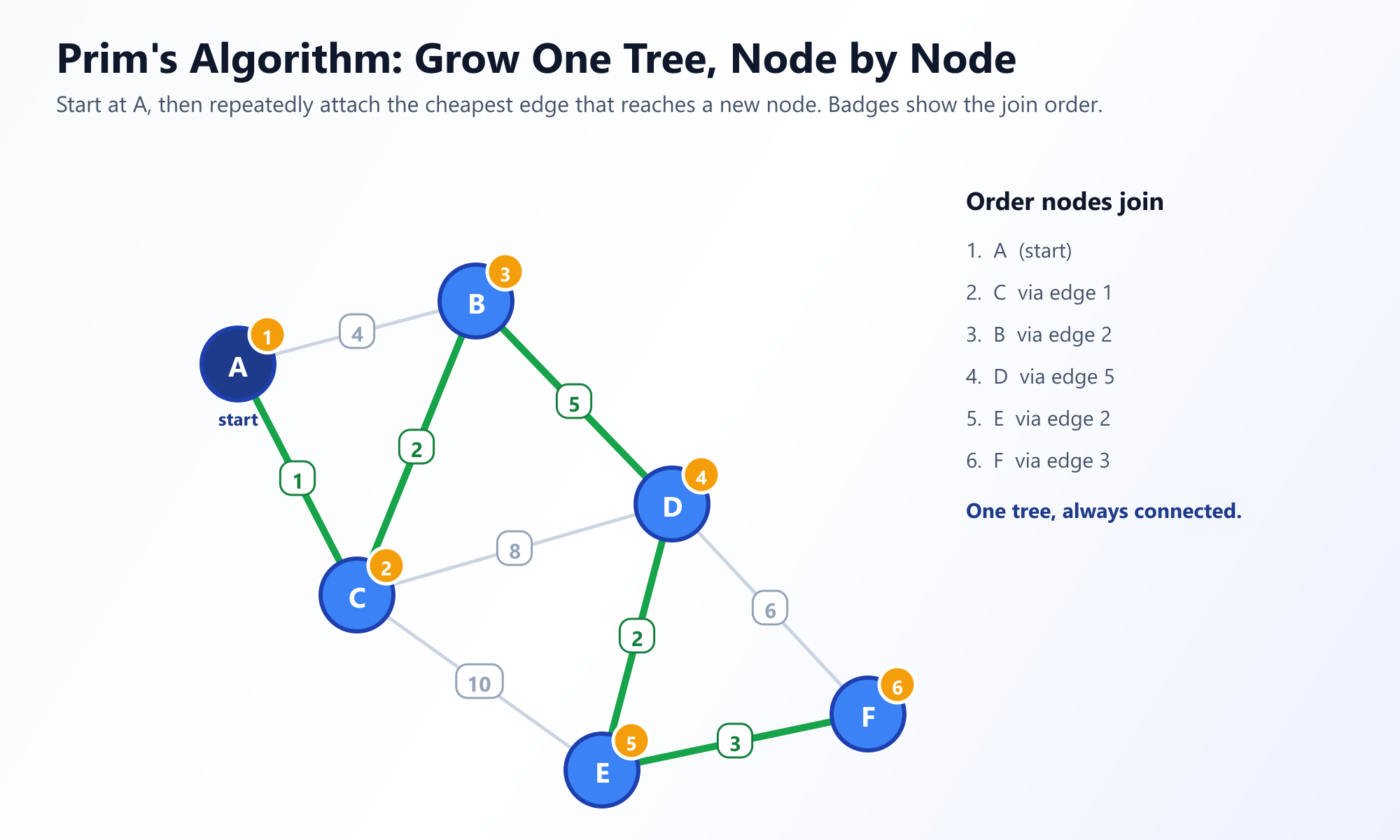
Visualisez la Croissance de l'Algorithme de Prim
Regardez comment la file de priorité évalue les arêtes de la "frontière" en temps réel. Voir l'arbre croître nœud par nœud est la meilleure façon d'intérioriser le choix glouton.
Lancer le Visualiseur Interactif de Prim3. Algorithme de Kruskal : L'Approche Centrée sur les Arêtes
Joseph Kruskal a publié son algorithme en 1956. Contrairement à Prim, qui fait croître un seul arbre continu à partir d'une racine, Kruskal adopte une approche centrée sur les arêtes. Il considère le graphe dans son ensemble, se concentrant entièrement sur les arêtes plutôt que sur les nœuds.
La Stratégie : Mettez toutes les arêtes dans un tas et triez-les du poids le plus faible au poids le plus élevé. Prenez la plus petite arête. Si l'ajout de cette arête à votre MST ne crée pas de cycle, gardez-la. Si elle crée un cycle, jetez-la. Répétez jusqu'à ce que vous ayez V - 1 arêtes.
Initialement, l'algorithme de Kruskal traite chaque nœud comme son propre arbre séparé. À mesure qu'il ajoute des arêtes, il fusionne ces petits arbres en forêts plus grandes, jusqu'à ce qu'il n'y ait finalement qu'un seul arbre massif couvrant l'ensemble du graphe.
4. L'Ingrédient Secret : Ensembles Disjoints (Union-Find)
Toute la logique de l'algorithme de Kruskal repose sur une étape cruciale : "Si l'ajout de cette arête ne crée pas de cycle."
Comment pouvons-vous déterminer efficacement si la connexion du Nœud A et du Nœud B créera un cycle ? Exécuter un DFS complet chaque fois que nous voulons ajouter une arête serait extrêmement lent. C'est là que la brillante structure de données des Ensembles Disjoints (Union-Find) vient à la rescousse.
Une structure de données Union-Find garde la trace des éléments partitionnés en un certain nombre de sous-ensembles disjoints (qui ne se chevauchent pas). Elle prend en charge deux opérations principales en temps presque constant O(1) :
- Find (Trouver) : Déterminer à quel ensemble appartient un élément particulier. (Généralement en trouvant la "racine" ou le "représentant" de l'ensemble).
- Union : Joindre (fusionner) deux sous-ensembles en un seul sous-ensemble.
Lors de l'évaluation d'une arête entre le Nœud A et le Nœud B, nous appelons simplement Find(A) et Find(B). S'ils renvoient la même racine, ils sont déjà dans la même composante connexe, ce qui signifie que l'ajout d'une arête entre eux créerait un cycle. S'ils renvoient des racines différentes, il est sûr d'ajouter l'arête, et nous appelons Union(A, B).
Algorithme de Kruskal en Python
class UnionFind:
def __init__(self, size):
# Initialement, chaque nœud est son propre parent (racine)
self.parent = [i for i in range(size)]
self.rank = [0] * size
def find(self, i):
# Optimisation de la compression de chemin
if self.parent[i] == i:
return i
self.parent[i] = self.find(self.parent[i])
return self.parent[i]
def union(self, i, j):
root_i = self.find(i)
root_j = self.find(j)
if root_i != root_j:
# Optimisation de l'union par rang
if self.rank[root_i] < self.rank[root_j]:
self.parent[root_i] = root_j
elif self.rank[root_i] > self.rank[root_j]:
self.parent[root_j] = root_i
else:
self.parent[root_j] = root_i
self.rank[root_i] += 1
return True
return False
def kruskals_algorithm(vertices_count, edges):
# edges est une liste de tuples : [(poids, u, v), ...]
# Étape 1 : Trier toutes les arêtes par ordre non décroissant de leur poids
edges.sort()
uf = UnionFind(vertices_count)
mst = []
total_cost = 0
# Étape 2 : Itérer à travers les arêtes triées
for edge in edges:
poids, u, v = edge
# Si l'inclusion de cette arête ne provoque pas de cycle, incluez-la
if uf.union(u, v):
mst.append((u, v, poids))
total_cost += poids
# Optimisation : S'arrêter tôt si nous avons V-1 arêtes
if len(mst) == vertices_count - 1:
break
return mst, total_cost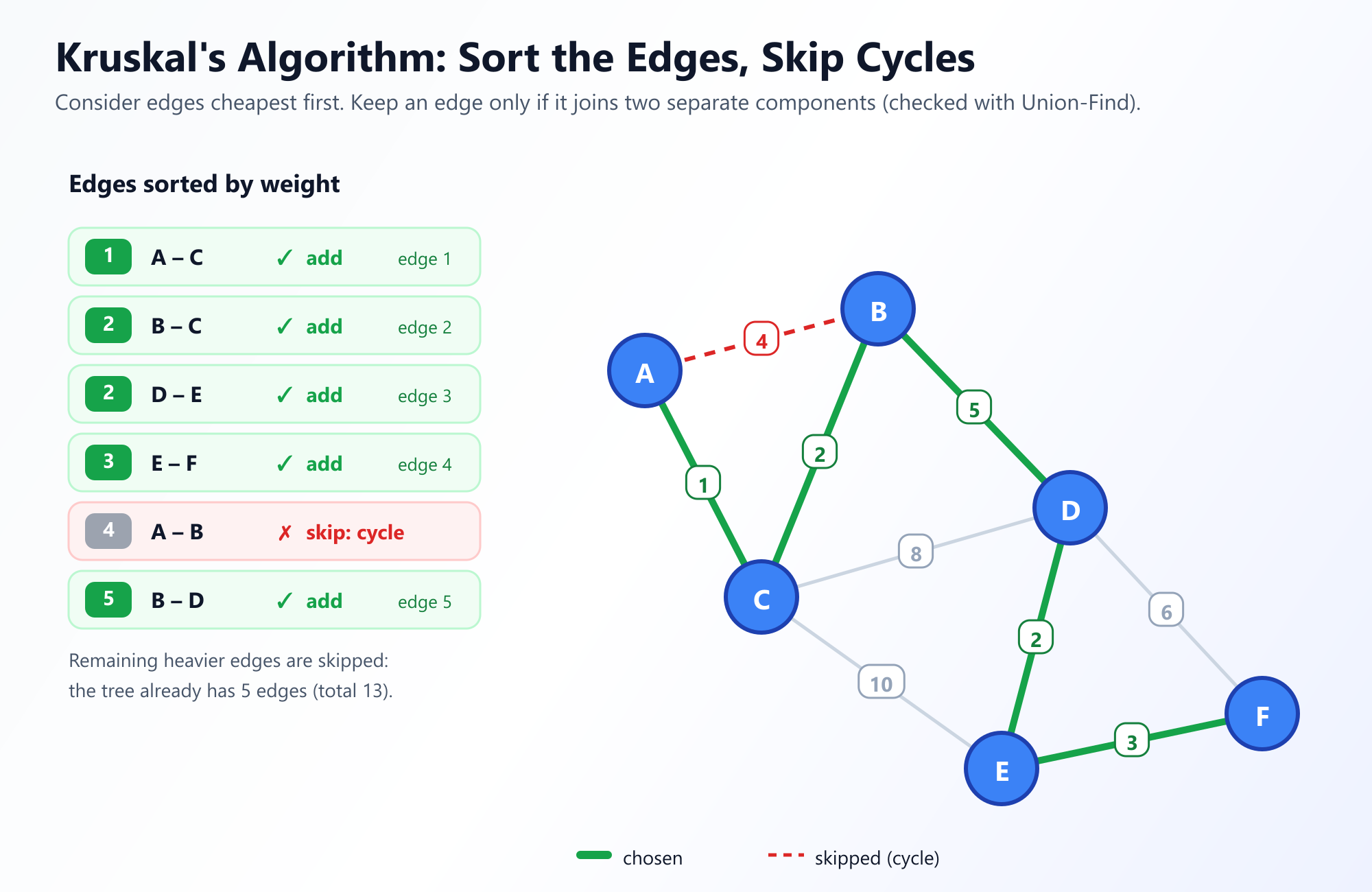
5. Prim vs. Kruskal : Lequel Choisir ?
Bien que les deux algorithmes soient garantis de trouver exactement le même poids d'arbre couvrant de poids minimum, leurs performances varient considérablement en fonction de la topologie du graphe traité.
| Métrique | Algorithme de Prim | Algorithme de Kruskal |
|---|---|---|
| Structure de Données | File de Priorité (Min-Heap) | Ensembles Disjoints (Union-Find) |
| Complexité Temporelle | O(E log V) en utilisant un tas binaire. |
O(E log E) ou O(E log V) fortement dominé par le tri des arêtes. |
| Densité du Graphe | Excellent pour les graphes denses. Comme il ne regarde que les arêtes adjacentes des nœuds visités, il est beaucoup plus performant lorsque le nombre d'arêtes E est proche de V². |
Excellent pour les graphes clairsemés. La première étape consistant à trier toutes les arêtes, avoir moins d'arêtes rend le tri fulgurant. |
| Complexité d'Implémentation | Peut être légèrement plus complexe en raison de la gestion de la file de priorité et du suivi des états visités. | Très simple à implémenter, à condition d'avoir une classe Union-Find pré-écrite. |
| Modèle de Croissance | Fait croître un seul arbre continu. | Fait croître une forêt d'arbres disjoints qui finissent par fusionner. |
6. Applications dans le Monde Réel des MST
L'Arbre Couvrant de Poids Minimum n'est pas qu'une construction théorique ; il est activement utilisé dans diverses disciplines d'ingénierie pour minimiser les coûts et optimiser le routage.
- Conception de Réseaux : Les télécommunications, les réseaux électriques, les réseaux d'approvisionnement en eau et les réseaux informatiques utilisent des algorithmes MST pour s'assurer que tous les nœuds sont connectés avec la quantité minimale de fils ou de tuyaux physiques.
- Algorithmes d'Approximation : Les MST sont fréquemment utilisés comme tremplin pour résoudre des problèmes NP-difficiles plus complexes, tels que l'approximation du problème du voyageur de commerce (TSP).
- Analyse de Regroupement (Clustering) : Dans l'apprentissage automatique et l'exploration de données, le regroupement à lien unique s'appuie sur l'algorithme de Kruskal pour regrouper les points de données en fonction de leur distance la plus courte avec d'autres grappes.
- Segmentation d'Images : Les algorithmes MST peuvent être utilisés pour partitionner une image en régions ou objets distincts en fonction de la similarité des pixels.
Foire aux questions
Qu'est-ce qu'un Arbre Couvrant Minimum (ACM/MST) ?
Un ACM est un sous-ensemble d'arêtes reliant tous les sommets d'un graphe connexe non orienté, sans cycle et de poids total minimal.
Comment Union-Find évite-t-il les cycles dans Kruskal ?
Union-Find suit les composants connexes. Si deux sommets d'une arête appartiennent déjà au même ensemble, l'ajouter créerait un cycle, elle est donc rejetée.
Un graphe peut-il avoir plusieurs ACM ?
Oui, si plusieurs arêtes ont le même poids. Si tous les poids d'arêtes sont uniques, l'arbre couvrant minimum est unique.