
Tabla de Contenidos
- 1. ¿Qué es un Árbol de Expansión Mínima?
- 2. Algoritmo de Prim: El Enfoque Centrado en Nodos
- 3. Algoritmo de Kruskal: El Enfoque Centrado en Aristas
- 4. El Ingrediente Secreto: Conjuntos Disjuntos (Union-Find)
- 5. Prim vs. Kruskal: ¿Cuál Elegir?
- 6. Aplicaciones en el Mundo Real
- Preguntas Frecuentes (FAQ)
1. ¿Qué es un Árbol de Expansión Mínima (MST)?
Imagina que te han asignado la tarea de diseñar una nueva red de telecomunicaciones para una ciudad. Tienes un mapa con varios vecindarios (nodos) y las posibles rutas donde puedes instalar cables de fibra óptica (aristas). Instalar cable es costoso y el costo varía dependiendo del terreno (pesos de las aristas).
Tu objetivo es asegurarte de que cada vecindario esté conectado a la red, lo que significa que hay un camino desde cualquier vecindario a cualquier otro vecindario. Sin embargo, para ahorrar dinero, quieres que el costo total de instalar los cables sea lo menor posible. No necesitas conexiones redundantes; mientras todo esté conectado, estás satisfecho.
Este escenario exacto es la definición de libro de texto del problema del Árbol de Expansión Mínima (Minimum Spanning Tree, MST).
Desglosemos la terminología:
- Árbol: Un grafo conectado sin absolutamente ningún ciclo. Si tienes
Vvértices, un árbol siempre tendrá exactamenteV - 1aristas. - De Expansión: Cubre (expande) cada uno de los vértices en el grafo original.
- Mínima: Entre todos los posibles árboles de expansión que podrían dibujarse sobre el grafo, este tiene el menor peso total de aristas.
Es importante tener en cuenta que un grafo podría tener múltiples Árboles de Expansión Mínima si varias aristas comparten los mismos pesos, pero el peso total mínimo siempre será único.
Para resolver este problema, la informática se basa en gran medida en dos algoritmos voraces legendarios: el Algoritmo de Prim y el Algoritmo de Kruskal.
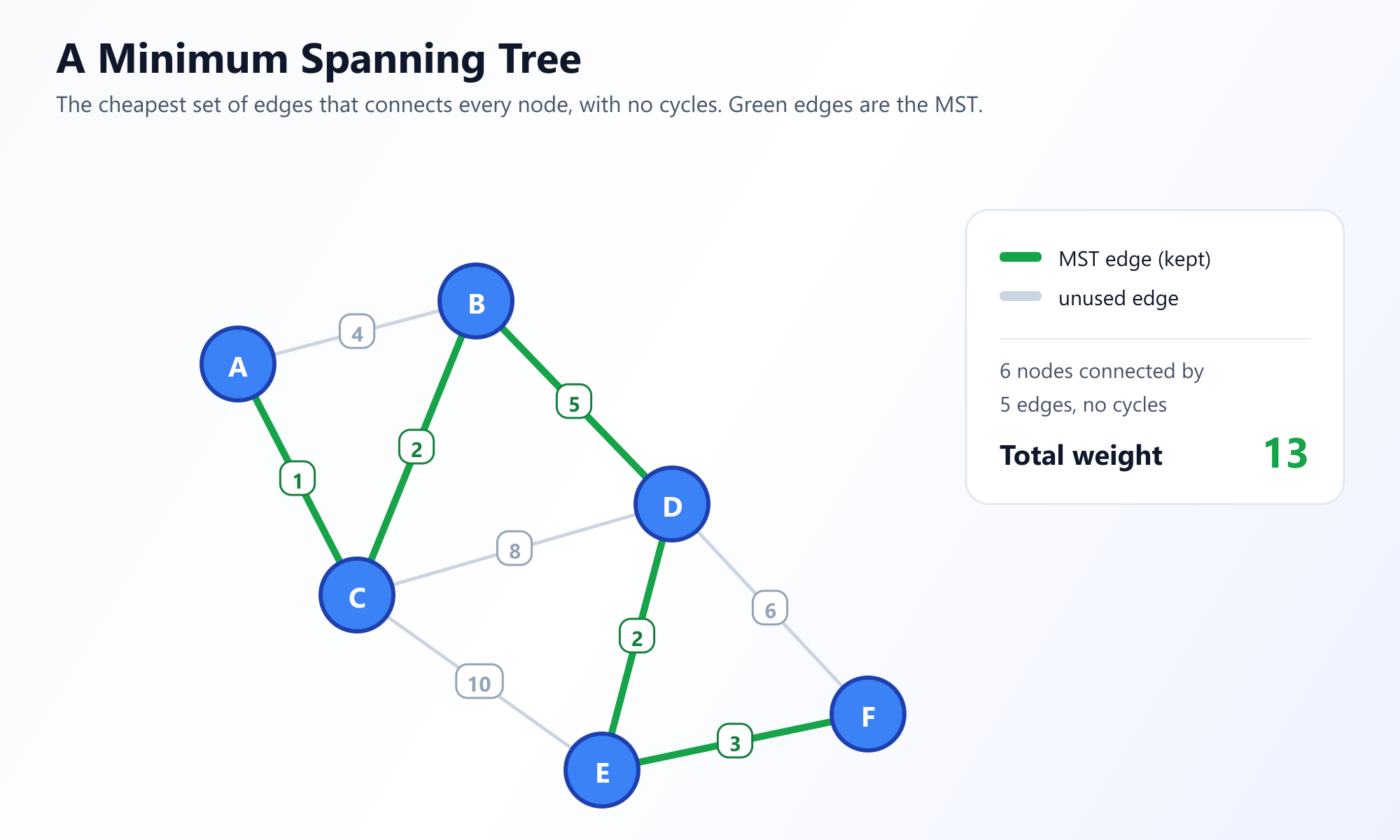
2. Algoritmo de Prim: El Enfoque Centrado en Nodos
El Algoritmo de Prim fue diseñado originalmente en 1930 por el matemático Vojtěch Jarník, y más tarde redescubierto y popularizado por Robert Prim en 1957. Prim toma un enfoque centrado en los nodos, haciendo crecer lentamente el árbol hacia afuera desde un solo vértice inicial, de forma muy parecida a como se propaga el moho en un trozo de pan.
La Estrategia: Comienza en cualquier nodo arbitrario. Observa todas las aristas que conectan los nodos en tu árbol actual en crecimiento con nodos fuera del árbol. Elige la arista con el peso más bajo. Agrega esa arista y el nuevo nodo a tu árbol. Repite hasta que todos los nodos estén incluidos.
La Mecánica
Para encontrar eficientemente la arista de menor peso que conecta el árbol con el mundo exterior, el algoritmo de Prim utiliza en gran medida una Cola de Prioridad (Min-Heap), lo que lo hace muy similar en estructura al algoritmo del Camino Más Corto de Dijkstra.
- Inicializa un arreglo booleano para realizar un seguimiento de los nodos que ya están incluidos en el MST.
- Inicializa una Cola de Prioridad para almacenar tuplas de
(peso_arista, nodo_destino). - Elige un nodo inicial aleatorio, márcalo como incluido e inserta todas sus aristas en la Cola de Prioridad.
- Mientras la Cola de Prioridad no esté vacía y el MST no tenga
V - 1aristas: - Extrae la arista con el peso mínimo.
- Si el nodo destino ya está en el MST, ignóralo (para prevenir ciclos).
- De lo contrario, agrega la arista al MST, marca el nuevo nodo como incluido e inserta todas las aristas que irradian de este nuevo nodo en la Cola de Prioridad.
Algoritmo de Prim en Python
import heapq
def prims_algorithm(graph, start_node):
# graph se representa como una lista de adyacencia:
# graph[u] = [(peso, v), ...]
mst = []
visited = set([start_node])
# Inicializa la cola de prioridad con las aristas del nodo inicial
edges = [ (peso, start_node, nodo_destino) for peso, nodo_destino in graph[start_node] ]
heapq.heapify(edges)
total_cost = 0
while edges:
peso, desde, hacia = heapq.heappop(edges)
# Si el destino no ha sido visitado, es una arista segura
if hacia not in visited:
visited.add(hacia)
mst.append((desde, hacia, peso))
total_cost += peso
# Inserta todas las aristas que se originan desde el nodo recién visitado
for peso_siguiente, hacia_siguiente in graph[hacia]:
if hacia_siguiente not in visited:
heapq.heappush(edges, (peso_siguiente, hacia, hacia_siguiente))
return mst, total_cost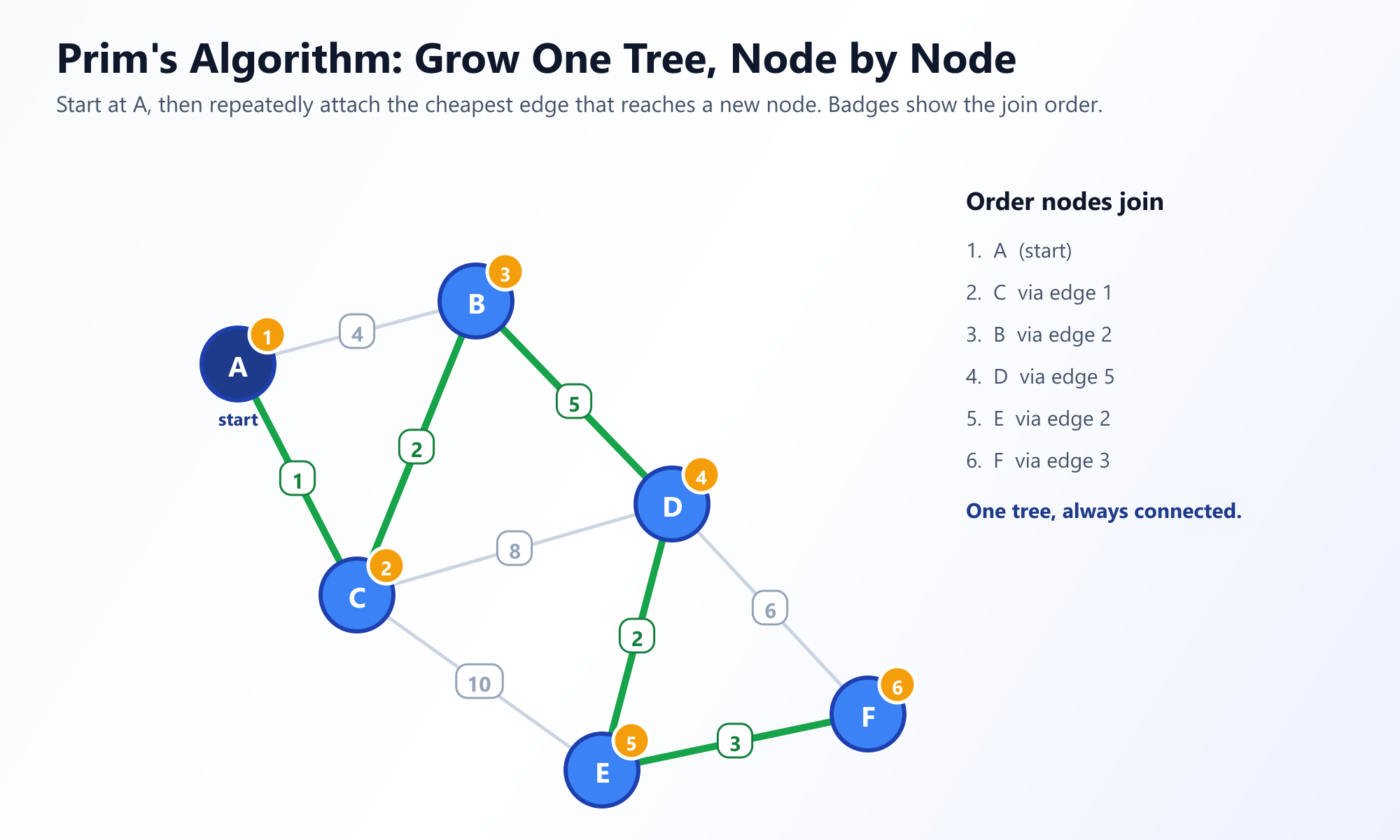
Visualiza el Crecimiento del Algoritmo de Prim
Observa cómo la Cola de Prioridad evalúa las aristas de la "frontera" en tiempo real. Ver crecer el árbol nodo a nodo es la mejor manera de internalizar la elección voraz.
Iniciar Visualizador Interactivo de Prim3. Algoritmo de Kruskal: El Enfoque Centrado en Aristas
Joseph Kruskal publicó su algoritmo en 1956. A diferencia de Prim, que hace crecer un único árbol continuo a partir de una raíz, Kruskal toma un enfoque centrado en las aristas. Observa el grafo en su conjunto, centrándose por completo en las aristas en lugar de en los nodos.
La Estrategia: Pon todas las aristas en un montón y ordénalas de menor a mayor peso. Toma la arista más pequeña. Si agregar esta arista a tu MST no crea un ciclo, consérvala. Si crea un ciclo, deséchala. Repite hasta que tengas V - 1 aristas.
Inicialmente, el algoritmo de Kruskal trata cada nodo como su propio árbol separado. A medida que agrega aristas, fusiona estos pequeños árboles en bosques más grandes, hasta que finalmente, solo hay un enorme árbol que abarca todo el grafo.
4. El Ingrediente Secreto: Conjuntos Disjuntos (Union-Find)
Toda la lógica del algoritmo de Kruskal depende de un paso crucial: "Si agregar esta arista no crea un ciclo."
¿Cómo podemos determinar eficientemente si conectar el Nodo A y el Nodo B creará un ciclo? Ejecutar un DFS completo cada vez que queramos agregar una arista sería dolorosamente lento. Aquí es donde la brillante estructura de datos de Conjuntos Disjuntos (Union-Find) viene al rescate.
Una estructura de datos Union-Find realiza un seguimiento de los elementos particionados en una serie de subconjuntos disjuntos (que no se superponen). Soporta dos operaciones principales en un tiempo casi constante de O(1):
- Find: Determinar a qué conjunto pertenece un elemento particular. (Por lo general, encontrando la "raíz" o "representante" del conjunto).
- Union: Unir (fusionar) dos subconjuntos en un solo subconjunto.
Al evaluar una arista entre el Nodo A y el Nodo B, simplemente llamamos a Find(A) y Find(B). Si devuelven la misma raíz, ya están en el mismo componente conectado, lo que significa que agregar una arista entre ellos crearía un ciclo. Si devuelven diferentes raíces, es seguro agregar la arista, y llamamos a Union(A, B).
Algoritmo de Kruskal en Python
class UnionFind:
def __init__(self, size):
# Inicialmente, cada nodo es su propio padre (raíz)
self.parent = [i for i in range(size)]
self.rank = [0] * size
def find(self, i):
# Optimización de compresión de caminos
if self.parent[i] == i:
return i
self.parent[i] = self.find(self.parent[i])
return self.parent[i]
def union(self, i, j):
root_i = self.find(i)
root_j = self.find(j)
if root_i != root_j:
# Optimización de unión por rango
if self.rank[root_i] < self.rank[root_j]:
self.parent[root_i] = root_j
elif self.rank[root_i] > self.rank[root_j]:
self.parent[root_j] = root_i
else:
self.parent[root_j] = root_i
self.rank[root_i] += 1
return True
return False
def kruskals_algorithm(vertices_count, edges):
# edges es una lista de tuplas: [(peso, u, v), ...]
# Paso 1: Ordenar todas las aristas en orden no decreciente de su peso
edges.sort()
uf = UnionFind(vertices_count)
mst = []
total_cost = 0
# Paso 2: Iterar a través de las aristas ordenadas
for edge in edges:
peso, u, v = edge
# Si incluir esta arista no causa un ciclo, inclúyela
if uf.union(u, v):
mst.append((u, v, peso))
total_cost += peso
# Optimización: Detenerse temprano si tenemos V-1 aristas
if len(mst) == vertices_count - 1:
break
return mst, total_cost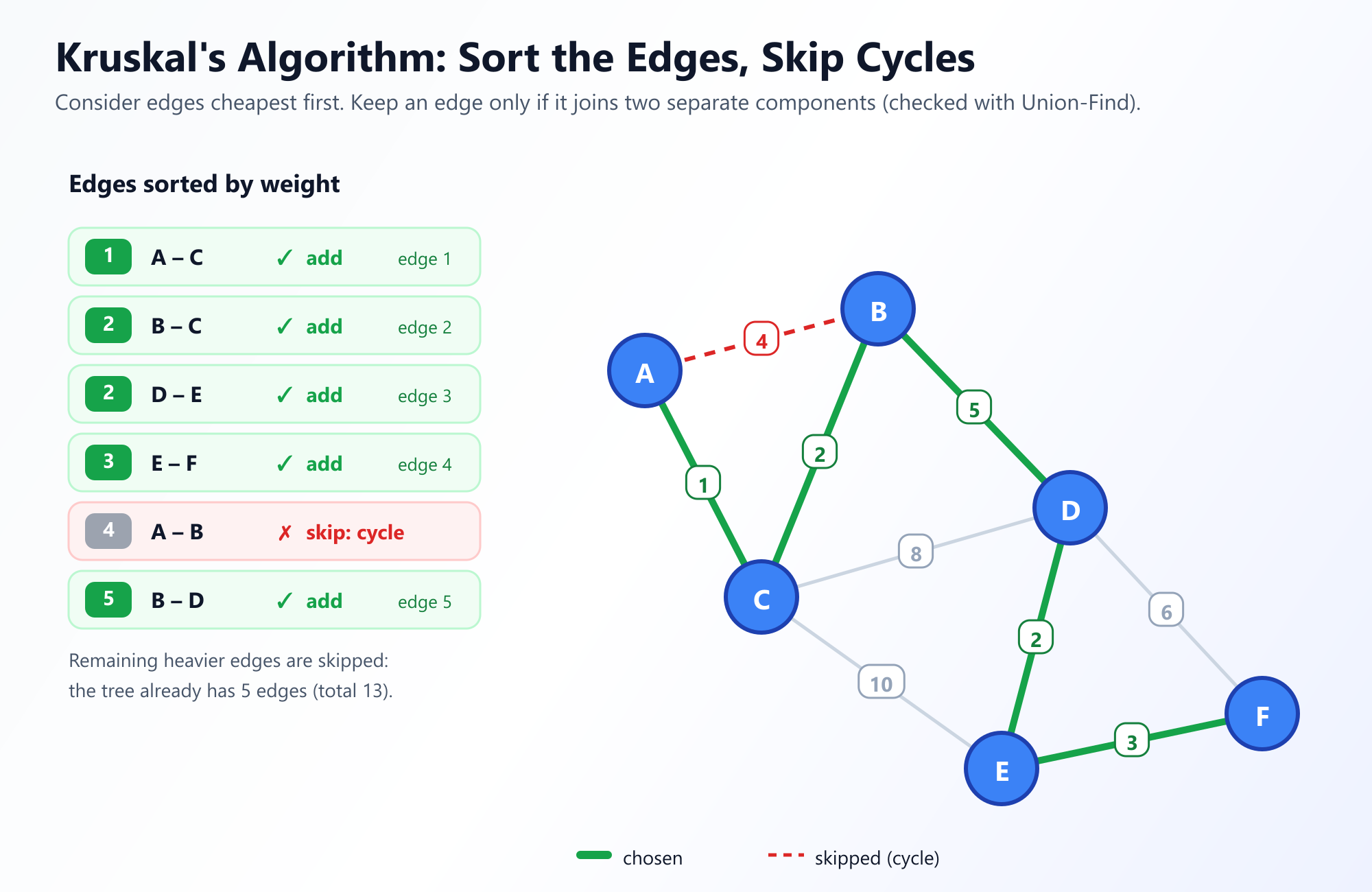
5. Prim vs. Kruskal: ¿Cuál Elegir?
Si bien se garantiza que ambos algoritmos encontrarán exactamente el mismo peso del árbol de expansión mínima, su rendimiento varía significativamente según la topología del grafo que se esté procesando.
| Métrica | Algoritmo de Prim | Algorithmo de Kruskal |
|---|---|---|
| Estructura de Datos | Cola de Prioridad (Min-Heap) | Conjuntos Disjuntos (Union-Find) |
| Complejidad Temporal | O(E log V) usando un montículo binario. |
O(E log E) u O(E log V) fuertemente dominado por la ordenación de las aristas. |
| Densidad del Grafo | Excelente para Grafos Densos. Dado que solo analiza las aristas adyacentes de los nodos visitados, funciona mucho mejor cuando el número de aristas E está cerca de V². |
Excelente para Grafos Dispersos. Dado que el primer paso es ordenar todas las aristas, tener menos aristas hace que la ordenación sea increíblemente rápida. |
| Complejidad de Implementación | Puede ser un poco más complejo debido al manejo de la cola de prioridad y el seguimiento de los estados visitados. | Muy sencillo de implementar, siempre y cuando tengas una clase Union-Find preescrita. |
| Patrón de Crecimiento | Hace crecer un árbol único y contiguo. | Hace crecer un bosque de árboles disjuntos que finalmente se fusionan. |
6. Aplicaciones en el Mundo Real de los MST
El Árbol de Expansión Mínima no es solo una construcción teórica; se utiliza activamente en diversas disciplinas de ingeniería para minimizar costos y optimizar el enrutamiento.
- Diseño de Redes: Las telecomunicaciones, redes eléctricas, redes de suministro de agua y redes informáticas utilizan algoritmos de MST para garantizar que todos los nodos estén conectados con la cantidad mínima de cable o tubería física.
- Algoritmos de Aproximación: Los MST se utilizan con frecuencia como un paso intermedio para resolver problemas NP-difíciles más difíciles, como la aproximación del Problema del Viajante (TSP).
- Análisis de Conglomerados (Clustering): En el aprendizaje automático y la minería de datos, la agrupación de enlace simple se basa en el algoritmo de Kruskal para agrupar puntos de datos en función de su distancia más corta a otros conglomerados.
- Segmentación de Imágenes: Los algoritmos MST se pueden usar para dividir una imagen en regiones u objetos distintos según la similitud de los píxeles.
Preguntas frecuentes
¿Qué es un Árbol de Expansión Mínimo (MST)?
Un MST es un subconjunto de aristas que conecta todos los vértices de un grafo ponderado no dirigido, sin ciclos y con el menor peso total posible.
¿Cómo evita Union-Find los ciclos en el algoritmo de Kruskal?
Union-Find agrupa componentes. Antes de añadir una arista entre u y v, Kruskal verifica si ya están en el mismo conjunto. Si es así, se descarta para evitar un ciclo.
¿Puede un grafo tener más de un MST?
Sí, si hay aristas con pesos repetidos. Si todos los pesos de las aristas son únicos, el Árbol de Expansión Mínimo es único.